文件属性与目录
在前面的章节内容中,都是围绕普通文件I/O操作进行的一系列讨论,譬如打开文件、读写文件、关闭文件等,本章将抛开文件I/O相关话题,来讨论Linux文件系统的其它特性以及文件相关属性;我们将从系统调用stat开始,可利用其返回一个包含多种文件属性(包括文件时间戳、文件所有权以及文件权限等)的结构体,逐个说明stat结构中的每一个成员以了解文件的所有属性,然后将向大家介绍用以改变文件属性的各种系统调用;除此之外,还会向大家介绍Linux系统中的符号链接以及目录相关的操作。
本章将会讨论如下主题内容。
Linux系统的文件类型;stat系统调用;文件各种属性介绍:文件属主、访问权限、时间戳;符号链接与硬链接;目录;删除文件与文件重命名。
Linux系统中的文件类型
Linux下一切皆文件,文件作为Linux系统设计思想的核心理念,在Linux系统下显得尤为重要。在前面章节内容中,我们都是以普通文件(文本文件、二进制文件等)为例来给大家讲解文件I/O相关的知识内容;虽然在Linux系统中大部分文件都是普通文件,但并不仅仅只有普通文件,那么本小节将向大家介绍Linux系统中的文件类型。
在Windows系统下,操作系统识别文件类型一般是通过文件名后缀来判断,譬如C语言头文件.h、C语言源文件.c、.txt文本文件、压缩包文件.zip等,在Windows操作系统下打开文件,首先会识别文件名后缀得到该文件的类型,然后再使用相应的调用相应的程序去打开它;譬如.c文件,则会使用C代码编辑器去打开它;.zip文件,则会使用解压软件去打开它。
但是在Linux系统下,并不会通过文件后缀名来识别一个文件的类型,话虽如此,但并不是意味着大家可以随便给文件加后缀;文件名也好、后缀也好都是给“人”看的,虽然Linux系统并不会通过后缀来识别文件,但是文件后缀也要规范、需要根据文件本身的功能属性来添加,譬如C源文件就以.c为后缀、C头文件就以.h为后缀、shell脚本文件就以.sh为后缀、这是为了我们自己方便查看、浏览。
Linux系统下一共分为7种文件类型,下面依次给大家介绍。
普通文件
普通文件(regular file)在Linux系统下是最常见的,譬如文本文件、二进制文件,我们编写的源代码文件这些都是普通文件,也就是一般意义上的文件。普通文件中的数据存在系统磁盘中,可以访问文件中的内容,文件中的内容以字节为单位进行存储于访问。
普通文件可以分为两大类:文本文件和二进制文件。
文本文件:文件中的内容是由文本构成的,所谓文本指的是ASCII码字符。文件中的内容其本质上都是数字(因为计算机本身只有0和1,存储在磁盘上的文件内容也都是由0和1所构成),而文本文件中的数字应该被理解为这个数字所对应的ASCII字符码;譬如常见的.c、.h、.sh、.txt等这些都是文本文件,文本文件的好处就是方便人阅读、浏览以及编写。二进制文件:二进制文件中存储的本质上也是数字,只不过对于二进制文件来说,这些数字并不是文本字符编码,而是真正的数字。譬如Linux系统下的可执行文件、C代码编译之后得到的.o文件、.bin文件等都是二进制文件。
在Linux系统下,可以通过stat命令或者ls命令来查看文件类型,如下所示:
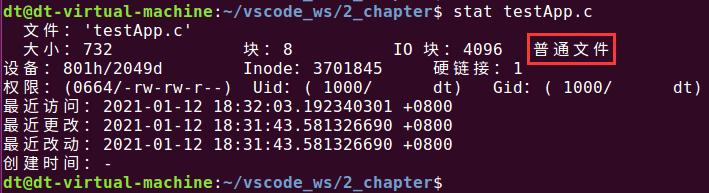
图 5.1.1 stat查看文件类型图

图 5.1.2 ls查看文件类型
stat命令非常友好,会直观把文件类型显示出来;对于ls命令来说,并没有直观的显示出文件的类型,而是通过符号表示出来,在图 5.1.2中画红色框位置显示出的一串字符中,其中第一个字符(' - ')就用于表示文件的类型,减号' - '就表示该文件是一个普通文件;除此之外,来看看其它文件类型使用什么字符表示:
' - ':普通文件' d ':目录文件' c ':字符设备文件' b ':块设备文件' l ':符号链接文件' s ':套接字文件' p ':管道文件
关于普通文件就给大家介绍这么多。
目录文件
目录(directory)就是文件夹,文件夹在Linux系统中也是一种文件,是一种特殊文件,同样我们也可以使用vi编辑器来打开文件夹,如下所示:
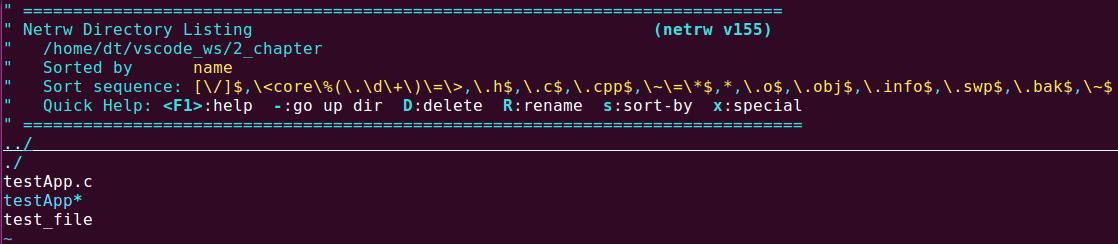
图 5.1.3 使用vi打开文件夹
可以看到,文件夹中记录了该文件夹本省的路径以及该文件夹下所存放的文件。文件夹作为一种特殊文件,本身并不适合使用前面给大家介绍的文件I/O的方式来读写,在Linux系统下,会有一些专门的系统调用用于读写文件夹,这部分内容后面再给大家介绍。
字符设备文件和块设备文件
学过Linux驱动编程开发的读者,对字符设备文件(character)、块设备文件(block)这些文件类型应该并不陌生,Linux系统下,一切皆文件,也包括各种硬件设备。设备文件(字符设备文件、块设备文件)对应的是硬件设备,在Linux系统中,硬件设备会对应到一个设备文件,应用程序通过对设备文件的读写来操控、使用硬件设备,譬如LCD显示屏、串口、音频、按键等,在本教程的进阶篇内容中,将会向大家介绍如何通过设备文件操控、使用硬件设备。
Linux系统中,可将硬件设备分为字符设备和块设备,所以就有了字符设备文件和块设备文件两种文件类型。虽然有设备文件,但是设备文件并不对应磁盘上的一个文件,也就是说设备文件并不存在于磁盘中,而是由文件系统虚拟出来的,一般是由内存来维护,当系统关机时,设备文件都会消失;字符设备文件一般存放在Linux系统/dev/目录下,所以/dev也称为虚拟文件系统devfs。以Ubuntu系统为例,如下所示:
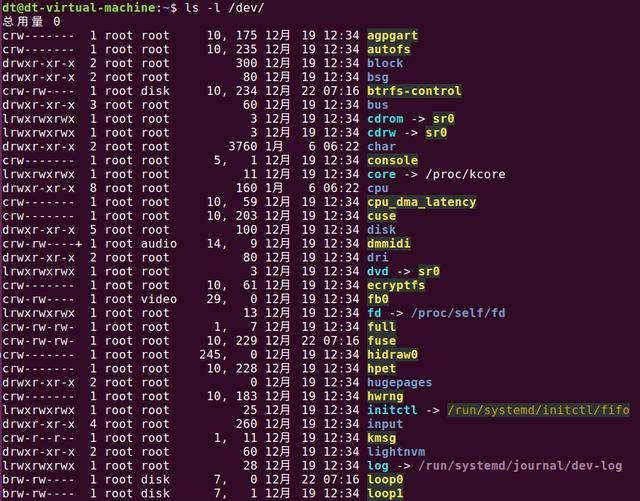
图 5.1.4 /dev目录下的设备文件
上图中agpgart、autofs、btrfs-control、console等这些都是字符设备文件,而loop0、loop1这些便是块设备文件。
符号链接文件
符号链接文件(link)类似于Windows系统中的快捷方式文件,是一种特殊文件,它的内容指向的是另一个文件路径,当对符号链接文件进行操作时,系统根据情况会对这个操作转移到它指向的文件上去,而不是对它本身进行操作,譬如,读取一个符号链接文件内容时,实际上读到的是它指向的文件的内容。
如果大家理解了Windows下的快捷方式,那么就会很容易理解Linux下的符号链接文件。图 5.1.4中的cdrom、cdrw、fd、initctl等这些文件都是符号链接文件,箭头所指向的文件路径便是符号链接文件所指向的文件。
关于链接文件,在后面的内容中还会给大家进行介绍,这里暂时给大家介绍这么多!
管道文件
管道文件(pipe)主要用于进程间通信,当学习到相关知识内容的时候再给大家详解。
套接字文件
套接字文件(socket)也是一种进程间通信的方式,与管道文件不同的是,它们可以在不同主机上的进程间通信,实际上就是网络通信,当学习到网络编程相关知识内容再给大家介绍。
总结
本小节给大家简单地介绍了Linux系统中的7种文件类型,包括:普通文件、目录、字符设备文件、块设备文件、符号链接文件、管道文件以及套接字文件,下面对它们进行一个简单地概括:
普通文件是最常见的文件类型;
目录也是一种文件类型;
设备文件对应于硬件设备;
符号链接文件类似于Windows的快捷方式;
管道文件用于进程间通信;
套接字文件用于网络通信。
stat函数
Linux下可以使用stat命令查看文件的属性,其实这个命令内部就是通过调用stat()函数来获取文件属性的,stat函数是Linux中的系统调用,用于获取文件相关的信息,函数原型如下所示(可通过"man 2 stat"命令查看):
#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>int stat(const char *pathname, struct stat *buf);首先使用该函数需要包含<sys/types.h>、<sys/stat.h>以及<unistd.h>这三个头文件。
函数参数及返回值含义如下:
pathname:用于指定一个需要查看属性的文件路径。
buf:struct stat类型指针,用于指向一个struct stat结构体变量。调用stat函数的时候需要传入一个struct stat变量的指针,获取到的文件属性信息就记录在struct stat结构体中,稍后给大家介绍struct stat结构体中有记录了哪些信息。
返回值:成功返回0;失败返回-1,并设置error。
struct stat结构体
struct stat是内核定义的一个结构体,在<sys/stat.h>头文件中申明,所以可以在应用层使用,这个结构体中的所有元素加起来构成了文件的属性信息,结构体内容如下所示:
示例代码 5.2.1 struct stat结构体
struct stat{dev_t st_dev; /* 文件所在设备的ID */ino_t st_ino; /* 文件对应inode节点编号 */mode_t st_mode; /* 文件对应的模式 */nlink_t st_nlink; /* 文件的链接数 */uid_t st_uid; /* 文件所有者的用户ID */gid_t st_gid; /* 文件所有者的组ID */dev_t st_rdev; /* 设备号(指针对设备文件) */off_t st_size; /* 文件大小(以字节为单位) */blksize_t st_blksize; /* 文件内容存储的块大小 */blkcnt_t st_blocks; /* 文件内容所占块数 */struct timespec st_atim; /* 文件最后被访问的时间 */struct timespec st_mtim; /* 文件内容最后被修改的时间 */struct timespec st_ctim; /* 文件状态最后被改变的时间 */};
st_dev:该字段用于描述此文件所在的设备。不常用,可以不用理会。
st_ino:文件的inode编号。
st_mode:该字段用于描述文件的模式,譬如文件类型、文件权限都记录在该变量中,关于该变量的介绍请看5.2.2小节。
st_nlink:该字段用于记录文件的硬链接数,也就是为该文件创建了多少个硬链接文件。链接文件可以分为软链接(符号链接)文件和硬链接文件,关于这些内容后面再给大家介绍。
st_uid、st_gid:此两个字段分别用于描述文件所有者的用户ID以及文件所有者的组ID,后面再给大家介绍。
st_rdev:该字段记录了设备号,设备号只针对于设备文件,包括字符设备文件和块设备文件,不用理会。
st_size:该字段记录了文件的大小(逻辑大小),以字节为单位。
st_atim、st_mtim、st_ctim:此三个字段分别用于记录文件最后被访问的时间、文件内容最后被修改的时间以及文件状态最后被改变的时间,都是struct timespec类型变量,具体介绍请看5.2.3小节。
st_mode变量
st_mode是struct stat结构体中的一个成员变量,是一个32位无符号整形数据,该变量记录了文件的类型、文件的权限这些信息,其表示方法如下所示:

图 5.2.1 st_mode数据信息示意图
看到图 5.2.1的时候,大家有没有似曾相识的感觉,确实,前面章节内容给大家介绍open函数的第三个参数mode时也用到了类似的图,如图 2.3.2所示。唯一不同的在于open函数的mode参数只涉及到S、U、G、O这12个bit位,并不包括用于描述文件类型的4个bit位。
O对应的3个bit位用于描述其它用户的权限;
G对应的3个bit位用于描述同组用户的权限;
U对应的3个bit位用于描述文件所有者的权限;
S对应的3个bit位用于描述文件的特殊权限。
这些bit位表达内容与open函数的mode参数相对应,这里不再重述。同样,在mode参数中表示权限的宏定义,在这里也是可以使用的,这些宏定义如下(以下数字使用的是八进制方式表示):
S_IRWXU 00700 owner has read, write, and execute permissionS_IRUSR 00400 owner has read permissionS_IWUSR 00200 owner has write permissionS_IXUSR 00100 owner has execute permissionS_IRWXG 00070 group has read, write, and execute permissionS_IRGRP 00040 group has read permissionS_IWGRP 00020 group has write permissionS_IXGRP 00010 group has execute permissionS_IRWXO 00007 others (not in group) have read, write, and execute permissionS_IROTH 00004 others have read permissionS_IWOTH 00002 others have write permissionS_IXOTH 00001 others have execute permission
譬如,判断文件所有者对该文件是否具有可执行权限,可以通过以下方法测试(假设st是struct stat类型变量):
if (st.st_mode & S_IXUSR) {
//有权限
} else {
//无权限
}
这里我们重点来看看“文件类型”这4个bit位,这4个bit位用于描述该文件的类型,譬如该文件是普通文件、还是链接文件、亦或者是一个目录等,那么就可以通过这4个bit位数据判断出来,如下所示:
S_IFSOCK 0140000 socket(套接字文件)
S_IFLNK 0120000 symbolic link(链接文件)
S_IFREG 0100000 regular file(普通文件)
S_IFBLK 0060000 block device(块设备文件)
S_IFDIR 0040000 directory(目录)
S_IFCHR 0020000 character device(字符设备文件)
S_IFIFO 0010000 FIFO(管道文件)
注意上面这些数字使用的是八进制方式来表示的,在C语言中,八进制方式表示一个数字需要在数字前面添加一个0(零)。所以由上面可知,当“文件类型”这4个bit位对应的数字是14(八进制)时,表示该文件是一个套接字文件、当“文件类型”这4个bit位对应的数字是12(八进制)时,表示该文件是一个链接文件、当“文件类型”这4个bit位对应的数字是10(八进制)时,表示该文件是一个普通文件等。
所以通过st_mode变量判断文件类型就很简单了,如下(假设st是struct stat类型变量):
/* 判断是不是普通文件 */if ((st.st_mode & S_IFMT) == S_IFREG) {/* 是 */}/* 判断是不是链接文件 */if ((st.st_mode & S_IFMT) == S_IFLNK) {/* 是 */}S_IFMT宏是文件类型字段位掩码:S_IFMT 0170000
除了这样判断之外,我们还可以使用Linux系统封装好的宏来进行判断,如下所示(m是st_mode变量):
S_ISREG(m) #判断是不是普通文件,如果是返回true,否则返回falseS_ISDIR(m) #判断是不是目录,如果是返回true,否则返回falseS_ISCHR(m) #判断是不是字符设备文件,如果是返回true,否则返回falseS_ISBLK(m) #判断是不是块设备文件,如果是返回true,否则返回falseS_ISFIFO(m) #判断是不是管道文件,如果是返回true,否则返回falseS_ISLNK(m) #判断是不是链接文件,如果是返回true,否则返回falseS_ISSOCK(m) #判断是不是套接字文件,如果是返回true,否则返回false
有了这些宏之后,就可以通过如下方式来判断文件类型了:
/* 判断是不是普通文件 */if (S_ISREG(st.st_mode)) {/* 是 */}/* 判断是不是目录 */if (S_ISDIR(st.st_mode)) {/* 是 */}
关于st_mode变量就给大家介绍这么多。
struct timespec结构体
该结构体定义在<time.h>头文件中,是Linux系统中时间相关的结构体。应用程序中包含了<time.h>头文件,就可以在应用程序中使用该结构体了,结构体内容如下所示:
示例代码 5.2.2 struct timespec结构体
struct timespec{time_t tv_sec; /* 秒 */syscall_slong_t tv_nsec; /* 纳秒 */};
struct timespec结构体中只有两个成员变量,一个秒(tv_sec)、一个纳秒(tv_nsec),time_t其实指的就是long int类型,所以由此可知,该结构体所表示的时间可以精确到纳秒,当然,对于文件的时间属性来说,并不需要这么高的精度,往往只需精确到秒级别即可。
在Linux系统中,time_t时间指的是一个时间段,从某一个时间点到某一个时间点所经过的秒数,譬如对于文件的三个时间属性来说,指的是从过去的某一个时间点(这个时间点是一个起始基准时间点)到文件最后被访问、文件内容最后被修改、文件状态最后被改变的这个时间点所经过的秒数。time_t时间在Linux下被称为日历时间,7.2小计中对此有详细介绍。
由示例代码 5.2.1可知,struct stat结构体中包含了三个文件相关的时间属性,但这里得到的仅仅只是以秒+微秒为单位的时间值,对于我们来说,并不利用查看,我们一般喜欢的是“2020-10-10 18:30:30”这种形式表示的时间,直观、明了,那有没有办法通过秒来得到这种形式表达的时间呢?答案当然是可以,譬如可以通过localtime()/localtime_r()或者strftime()来得到更利于我们查看的时间表达方式,关于这些函数的介绍以及使用方法在7.2.4小节有详细说明。
练习
到这里本小节内容就给大家介绍完了,主要给大家介绍了stat函数以及由此引出来的一系列知识内容。为了巩固本小节所学内容,这里出一些简单地编程练习题,大家可以根据本小节所学知识完成它。
(1)获取文件的inode节点编号以及文件大小,并将它们打印出来。
(2)获取文件的类型,判断此文件对于其它用户(Other)是否具有可读可写权限。
(3)获取文件的时间属性,包括文件最后被访问的时间、文件内容最后被修改的时间以及文件状态最后被改变的时间,并使用字符串形式将其打印出来,包括时间和日期、表示形式自定。
以上就是根据本小节内容整理出来的一些简单的编程练习题,下面笔者将给出对应的示例代码。
(1)编程实战练习1
示例代码 5.2.3 编程实战练习1
#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>#include <stdio.h>#include <stdlib.h>int main(void){struct stat file_stat;int ret;/* 获取文件属性 */ret = stat("./test_file", &file_stat);if (-1 == ret) {perror("stat error");exit(-1);}/* 打印文件大小和inode编号 */printf("file size: %ld bytes\n""inode number: %ld\n", file_stat.st_size,file_stat.st_ino);exit(0);}
测试之前先使用ls命令查看test_file文件的inode节点和大小,如下:

图 5.2.2 ls命令查看文件的inode编号和大小
从图中可以得知,此文件的大小为8864个字节,inode编号为3701841;接下来编译我们的测试程序、并运行:
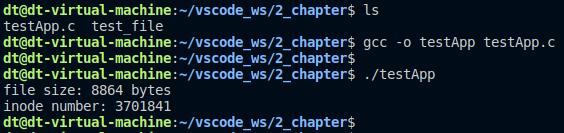
图 5.2.3 编程实战1测试结果
(2)编程实战练习2
示例代码 5.2.4 编程实战练习2
#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>#include <stdio.h>#include <stdlib.h>int main(void){struct stat file_stat;int ret;/* 获取文件属性 */ret = stat("./test_file", &file_stat);if (-1 == ret) {perror("stat error");exit(-1);}/* 判读文件类型 */switch (file_stat.st_mode & S_IFMT) {case S_IFSOCK: printf("socket"); break;case S_IFLNK: printf("symbolic link"); break;case S_IFREG: printf("regular file"); break;case S_IFBLK: printf("block device"); break;case S_IFDIR: printf("directory"); break;case S_IFCHR: printf("character device"); break;case S_IFIFO: printf("FIFO"); break;}printf("\n");/* 判断该文件对其它用户是否具有读权限 */if (file_stat.st_mode & S_IROTH)printf("Read: Yes\n");elseprintf("Read: No\n");/* 判断该文件对其它用户是否具有写权限 */if (file_stat.st_mode & S_IWOTH)printf("Write: Yes\n");elseprintf("Write: No\n");exit(0);}
测试:
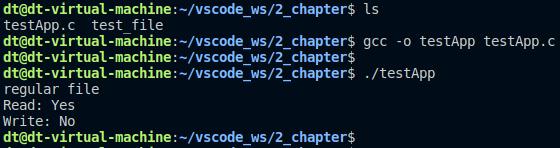
图 5.2.4 编程实战2测试结果
(3)编程实战练习3
示例代码 5.2.5 编程实战练习3
#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>#include <stdio.h>#include <stdlib.h>#include <time.h>int main(void){struct stat file_stat;struct tm file_tm;char time_str[100];int ret;/* 获取文件属性 */ret = stat("./test_file", &file_stat);if (-1 == ret) {perror("stat error");exit(-1);}/* 打印文件最后被访问的时间 */localtime_r(&file_stat.st_atim.tv_sec, &file_tm);strftime(time_str, sizeof(time_str),"%Y-%m-%d %H:%M:%S", &file_tm);printf("time of last access: %s\n", time_str);/* 打印文件内容最后被修改的时间 */localtime_r(&file_stat.st_mtim.tv_sec, &file_tm);strftime(time_str, sizeof(time_str),"%Y-%m-%d %H:%M:%S", &file_tm);printf("time of last modification: %s\n", time_str);/* 打印文件状态最后改变的时间 */localtime_r(&file_stat.st_ctim.tv_sec, &file_tm);strftime(time_str, sizeof(time_str),"%Y-%m-%d %H:%M:%S", &file_tm);printf("time of last status change: %s\n", time_str);exit(0);}
测试:
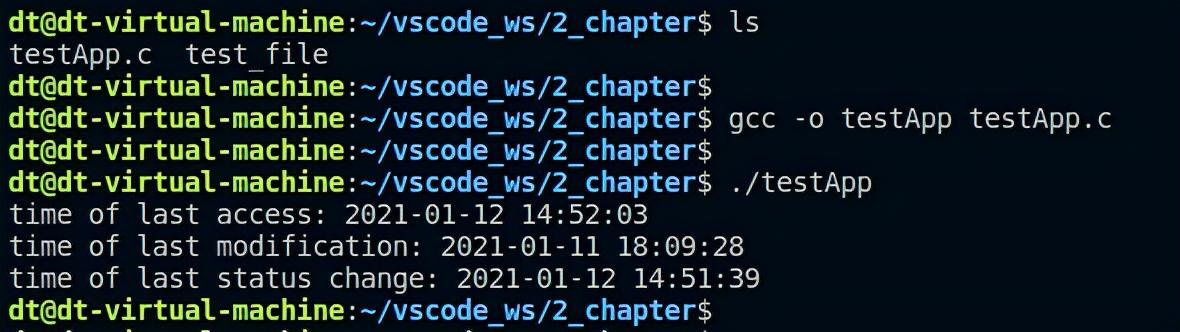
图 5.2.5 实战编程3测试结果
可以使用stat命令查看test_file文件的这些时间属性,对比程序打印出来是否正确:
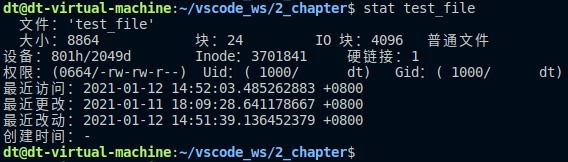
图 5.2.6 stat命令查看文件的时间属性
fstat和lstat函数
前面给大家介绍了stat系统调用,起始除了stat函数之外,还可以使用fstat和lstat两个系统调用来获取文件属性信息。fstat、lstat与stat的作用一样,但是参数、细节方面有些许不同。
fstat函数
fstat与stat区别在于,stat是从文件名出发得到文件属性信息,不需要先打开文件;而fstat函数则是从文件描述符出发得到文件属性信息,所以使用fstat函数之前需要先打开文件得到文件描述符。具体该用stat还是fstat,看具体的情况;譬如,并不想通过打开文件来得到文件属性信息,那么就使用stat,如果文件已经打开了,那么就使用fstat。
fstat函数原型如下(可通过"man 2 fstat"命令查看):
#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>int fstat(int fd, struct stat *buf);
第一个参数fd表示文件描述符,第二个参数以及返回值与stat一样。fstat函数使用示例如下:
示例代码 5.3.1 fstat函数使用示例
lstat函数
lstat()与stat、fstat的区别在于,对于符号链接文件,stat、fstat查阅的是符号链接文件所指向的文件对应的文件属性信息,而lstat查阅的是符号链接文件本身的属性信息。
lstat函数原型如下所示:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int lstat(const char *pathname, struct stat *buf);
函数参数列表、返回值与stat函数一样,使用方法也一样,这里不再重述!
文件属主
Linux是一个多用户操作系统,系统中一般存在着好几个不同的用户,而Linux系统中的每一个文件都有一个与之相关联的用户和用户组,通过这个信息可以判断文件的所有者和所属组。
文件所有者表示该文件属于“谁”,也就是属于哪个用户。一般来说文件在创建时,其所有者就是创建该文件的那个用户。譬如,当前登录用户为dt,使用touch命令创建了一个文件,那么这个文件的所有者就是dt;同理,在程序中调用open函数创建新文件时也是如此,执行该程序的用户是谁,其文件所有者便是谁。
文件所属组则表示该文件属于哪一个用户组。在Linux中,系统并不是通过用户名或用户组名来识别不同的用户和用户组,而是通过ID。ID就是一个编号,Linux系统会为每一个用户或用户组分配一个ID,将用户名或用户组名与对应的ID关联起来,所以系统通过用户ID(UID)或组ID(GID)就可以识别出不同的用户和用户组。
Tips:用户ID简称UID、用户组ID简称GID。这些都是Linux操作系统的基础知识,如果对用户和用户组的概念尚不熟悉,建议先自行学习这些基础知识。
譬如使用ls命令或stat命令便可以查看到文件的所有者和所属组,如下所示:
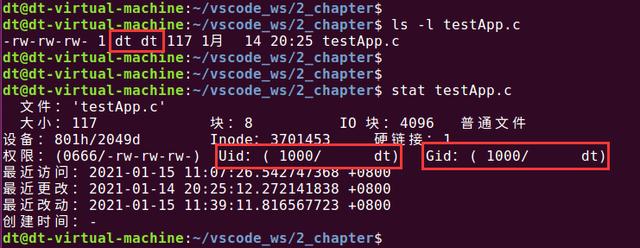
图 5.4.1 查看文件的所有者和所属组
图 5.4.1 查看文件的所有者和所属组
由上图可知,testApp.c文件的用户ID是1000,用户组ID也是1000。
文件的用户ID和组ID分别由struct stat结构体中的st_uid和st_gid所指定。既然Linux下的每一个文件都有与之相关联的用户ID和组ID,那么对于一个进程来说亦是如此,与一个进程相关联的ID有5个或更多,如下表所示:
表 5.4.1 与进程相关联的用户ID和组ID
ID类型
| 作用
| 实际用户ID
| 我们实际上是谁
| 实际组ID
| 有效用户ID
| 用于文件访问权限检查
| 有效组ID
| 附属组ID
|
实际用户ID和实际组ID标识我们究竟是谁,也就是执行该进程的用户是谁、以及该用户对应的所属组;实际用户ID和实际组ID确定了进程所属的用户和组。进程的有效用户ID、有效组ID以及附属组ID用于文件访问权限检查,详情请查看5.9.1小节内容。
有效用户ID和有效组ID
首先对于有效用户ID和有效组ID来说,这是进程所持有的概念,对于文件来说,并无此属性!有效用户ID和有效组ID是站在操作系统的角度,用于给操作系统判断当前执行该进程的用户在当前环境下对某个文件是否拥有相应的权限。
在Linux系统中,当进程对文件进行读写操作时,系统首先会判断该进程是否具有对该文件的读写权限,那如何判断呢?自然是通过该文件的权限位来判断,struct stat结构体中的st_mode字段中就记录了该文件的权限位以及文件类型。关于文件权限检查相关内容将会在5.5小节中说明。
当进行权限检查时,并不是通过进程的实际用户和实际组来参与权限检查的,而是通过有效用户和有效组来参与文件权限检查。通常,绝大部分情况下,进程的有效用户等于实际用户(有效用户ID等于实际用户ID),有效组等于实际组(有效组ID等于实际组ID)。
那么大家可能就要问了,什么情况下有效用户ID不等于实际用户ID、有效组ID不等于实际组ID?那么关于这个问题,后面将给大家揭晓!
Tips:文中所指的"进程对文件是否拥有xx权限"其实质是当前执行该进程的用户是否拥有对文件的xx权限。若无特别指出,文中的描述均为此意!
chown函数
chown是一个系统调用,该系统调用可用于改变文件的所有者(用户ID)和所属组(组ID)。其实在Linux系统下也有一个chown命令,该命令的作用也是用于改变文件的所有者和所属组,譬如将testApp.c文件的所有者和所属组修改为root:
sudo chown root:root testApp.c
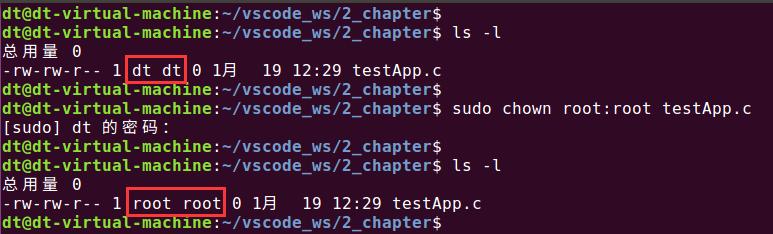
图 5.4.2 使用chown命令修改文件所有者和所属组
可以看到,通过该命令确实可以改变文件的所有者和所属组,这个命令内部其实就是调用了chown函数来实现功能的,chown函数原型如下所示(可通过"man 2 chown"命令查看):
#include <unistd.h>
int chown(const char *pathname, uid_t owner, gid_t group);
首先,使用该命令需要包含头文件<unistd.h>。
函数参数和返回值如下所示:
pathname:用于指定一个需要修改所有者和所属组的文件路径。
owner:将文件的所有者修改为该参数指定的用户(以用户ID的形式描述);
group:将文件的所属组修改为该参数指定的用户组(以用户组ID的形式描述);
返回值:成功返回0;失败将返回-1,兵并且会设置errno。
该函数的用法非常简单,只需指定对应的文件路径以及相应的owner和group参数即可!如果只需要修改文件的用户ID和用户组ID当中的一个,那么又该如何做呢?方法很简单,只需将其中不用修改的ID(用户ID或用户组ID)与文件当前的ID(用户ID或用户组ID)保持一致即可,即调用chown函数时传入的用户ID或用户组ID就是该文件当前的用户ID或用户组ID,而文件当前的用户ID或用户组ID可以通过stat函数查询获取。
虽然该函数用法很简单,但是有以下两个限制条件:
只有超级用户进程能更改文件的用户ID;普通用户进程可以将文件的组ID修改为其所从属的任意附属组ID,前提条件是该进程的有效用户ID等于文件的用户ID;而超级用户进程可以将文件的组ID修改为任意值。
所以,由此可知,文件的用户ID和组ID并不是随随便便就可以更改的,其实这种设计是为系统安全着想,如果系统中的任何普通用户进程都可以随便更改系统文件的用户ID和组ID,那么也就意味着任何普通用户对系统文件都有任意权限了,这对于操作系统来说将是非常不安全的。
测试
接下来看一些chown函数的使用例程,如下所示:
示例代码 5.4.1 chown函数使用示例
#include <unistd.h>#include <stdio.h>#include <stdlib.h>int main(void){if (-1 == chown("./test_file", 0, 0)) {perror("chown error");exit(-1);}exit(0);}
代码很简单,直接调用chown函数将test_file文件的用户ID和用户组ID修改为0、0。0指的就是root用户和root用户组,接下来我们测试下:
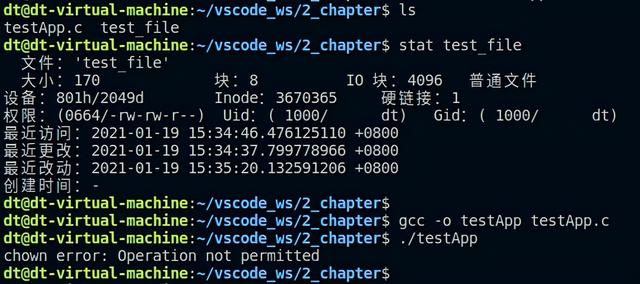
图 5.4.3 chown测试结果
在运行测试代码之前,先使用了stat命令查看到test_file文件的用户ID和用户组ID都等于1000,然后执行测试程序,结果报错"Operation not permitted",显示不允许操作;接下来重新执行程序,此时加上sudo,如下:
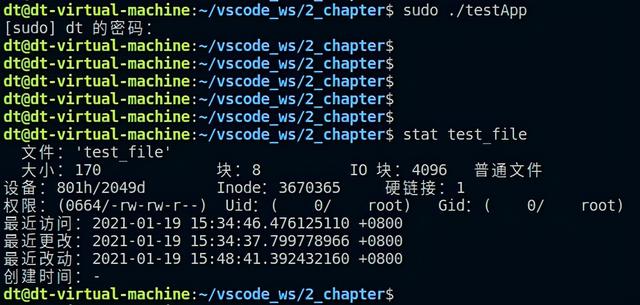
图 5.4.4 chown测试结果2图
此时便可以看到,执行之后没有打印错误提示信息,说明chown函数调用成功了,并且通过stat命令也可以看到文件的用户ID和组ID确实都被修改为0了(也就是root用户)。原因在于,加上sudo执行应用程序,而此时应用程序便可以临时获得root用户的权限,也就是会以root用户的身份运行程序,也就意味着此时该应用程序的用户ID(也就是前面给大家提到的实际用户ID)变成了root超级用户的ID(也就是0),自然chown函数便可以调用成功。
在Linux系统下,可以使用getuid和getgid两个系统调用分别用于获取当前进程的用户ID和用户组ID,这里说的进程的用户ID和用户组ID指的就是进程的实际用户ID和实际组ID,这两个系统调用函数原型如下所示:
#include <unistd.h>#include <sys/types.h>uid_t getuid(void);gid_t getgid(void);
我们可以在示例代码 5.4.1中加入打印用户ID的语句,如下所示:
示例代码 5.4.2 chown使用示例2
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
printf("uid: %d\n", getuid());
if(-1== chown("./test_file",0,0)){
perror("chown error");
exit(-1);
}
exit(0);
}
再来重复上面的测试:
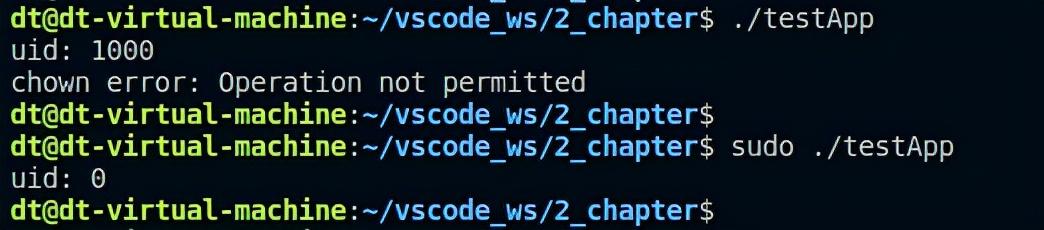
图 5.4.5 chown测试结果3
很明显可以看到两次执行同一个应用程序它们的用户ID是不一样的,因为加上了sudo使得应用程序的用户ID由原本的普通用户ID 1000变成了超级用户ID 0,使得该进程变成了超级用户进程,所以调用chown函数就不会报错。
关于chown就给大家介绍这么多,在实际应用编程中,此系统调用被用到的概率并不多,但是理论性知识还是得知道。
fchown和lchown函数
这两个同样也是系统调用,作用与chown函数相同,只是参数、细节方面有些许不同。fchown()、lchown()这两个函数与chown()的区别就像是fstat()、lstat()与stat的区别,本小节就不再重述这种问题了,如果大家对此还不清楚,可以看5.3小节,具体使用fchown、lchown还是chown,看情况而定。
文件访问权限
struct stat结构体中的st_mode字段记录了文件的访问权限位。当提及到文件时,指的是前面给大家介绍的任何类型的文件,并不仅仅指的是普通文件;所有文件类型(目录、设备文件)都有访问权限(access permission),可能有很多人认为只有普通文件才有访问权限,这是一种误解!
普通权限和特殊权限
文件的权限可以分为两个大类,分别是普通权限和特殊权限(也可称为附加权限)。普通权限包括对文件的读、写以及执行,而特殊权限则包括一些对文件的附加权限,譬如Set-User-ID、Set-Group-ID以及Sticky。接下来,分别对普通权限和特殊权限进行介绍。
普通权限
每个文件都有9个普通的访问权限位,可将它们分为3类,如下表:
st_mode权限表示宏
| 含义
|
S_IRUSR
S_IWUSR
S_IXUSR
|
文件所有者读权限
文件所有者写权限
文件所有者执行权限
|
S_IRGRP
S_IWGRP
S_IXGRP
|
同组用户读权限
同组用户写权限
同组用户执行权限
|
S_IROTH
S_IWOTH
S_IXOTH
|
其它用户读权限
其它用户写权限
其它用户执行权限
|
表 5.5.1 9个文件访问权限位
譬如使用ls命令或stat命令可以查看到文件的这9个访问权限,如下所示:
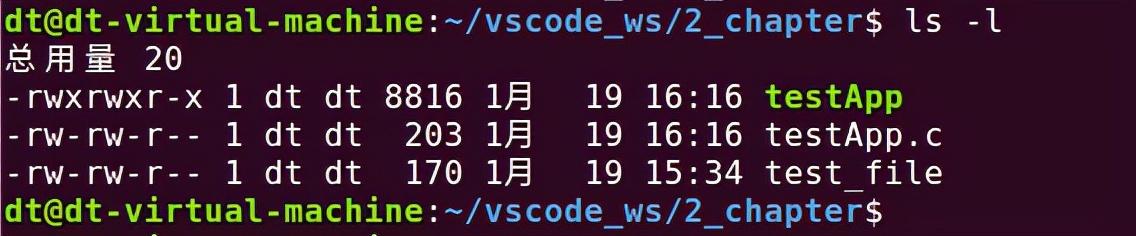
图 5.5.1 ls命令查看文件的9个访问权限位
每一行打印信息中,前面的一串字符串就描述了该文件的9个访问权限以及文件类型,譬如"-rwxrwxr-x":

图 5.5.2 文件权限位
最前面的一个字符表示该文件的类型,这个前面给大家介绍过," - "表示该文件是一个普通文件。
r表示具有读权限;
w表示具有写权限;
x表示具有执行权限;
-表示无此权限。
当进程每次对文件进行读、写、执行等操作时,内核就会对文件进行访问权限检查,以确定该进程对文件是否拥有相应的权限。而文件的权限检查就涉及到了文件的所有者(st_uid)、文件所属组(st_gid)以及其它用户,当然这里指的是从文件的角度来看;而对于进程来说,参与文件权限检查的是进程的有效用户、有效用户组以及进程的附属组用户。
如何判断权限,首先要搞清楚该进程对于需要进行操作的文件来说是属于哪一类“角色”:
如果进程的有效用户ID等于文件所有者ID(st_uid),意味着该进程以文件所有者的角色存在;如果进程的有效用户ID并不等于文件所有者ID,意味着该进程并不是文件所有者身份;但是进程的有效用户组ID或进程的附属组ID之一等于文件的组ID(st_gid),那么意味着该进程以文件所属组成员的角色存在,也就是文件所属组的同组用户成员。如果进程的有效用户ID不等于文件所有者ID、并且进程的有效用户组ID或进程的所有附属组ID均不等于文件的组ID(st_gid),那么意味着该进程以其它用户的角色存在。如果进程的有效用户ID等于0(root用户),则无需进行权限检查,直接对该文件拥有最高权限。
确定了进程对于文件来说是属于哪一类“角色”之后,相应的权限就直接“对号入座”即可。接下来聊一聊文件的附加的特殊权限。
特殊权限
st_mode字段中除了记录文件的9个普通权限之外,还记录了文件的3个特殊权限,也就是图 5.2.1中所表示的S字段权限位,S字段三个bit位中,从高位到低位依次表示文件的set-user-ID位权限、set-group-ID位权限以及sticky位权限,如下所示:
特殊权限
| 含义
| S_ISUID
|
set-user-ID位权限
| S_ISGID
|
set-group-ID位权限
| S_ISVTX
|
Sticky位权限
|
表 5.5.2 文件的特殊权限位
这三种权限分别使用S_ISUID、S_ISGID和S_ISVTX三个宏来表示:
S_ISUID 04000 set-user-ID bit
S_ISGID 02000 set-group-ID bit (see below)
S_ISVTX 01000 sticky bit (see below)
同样,以上数字使用的是八进制方式表示。对应的bit位数字为1,则表示设置了该权限、为0则表示并未设置该权限;譬如通过st_mode变量判断文件是否设置了set-user-ID位权限,代码如下:
if (st.st_mode & S_ISUID) {
//设置了set-user-ID位权限
} else {
//没有设置set-user-ID位权限
}
这三个权限位具体有什么作用呢?接下里给大家简单地介绍一下:
当进程对文件进行操作的时候、将进行权限检查,如果文件的set-user-ID位权限被设置,内核会将进程的有效ID设置为该文件的用户ID(文件所有者ID),意味着该进程直接获取了文件所有者的权限、以文件所有者的身份操作该文件。当进程对文件进行操作的时候、将进行权限检查,如果文件的set-group-ID位权限被设置,内核会将进程的有效用户组ID设置为该文件的用户组ID(文件所属组ID),意味着该进程直接获取了文件所属组成员的权限、以文件所属组成员的身份操作该文件。
看到这里,大家可能就要问了,如果两个权限位同时被设置呢?关于这个问题,我们后面可以进行相应的测试,答案自然会揭晓!
当然,set-user-ID位和set-group-ID位权限的作用并不如此简单,关于其它的功能本文档便不再叙述了,因为这些特殊权限位实际中用到的机会确实不多。除此之外,Sticky位权限也不再给大家介绍了,笔者对此也不是很了解,有兴趣的读者可以自行查阅相关的书籍。
Linux系统下绝大部分的文件都没有设置set-user-ID位权限和set-group-ID位权限,所以通常情况下,进程的有效用户等于实际用户(有效用户ID等于实际用户ID),有效组等于实际组(有效组ID等于实际组ID)。
目录权限
前面我们一直谈论的都是文件的读、写、执行权限,那对于创建文件、删除文件等这些操作难道就不需要相应的权限了吗?事实并不如此,譬如:有时删除文件或创建文件也会提示"权限不够",如下所示:
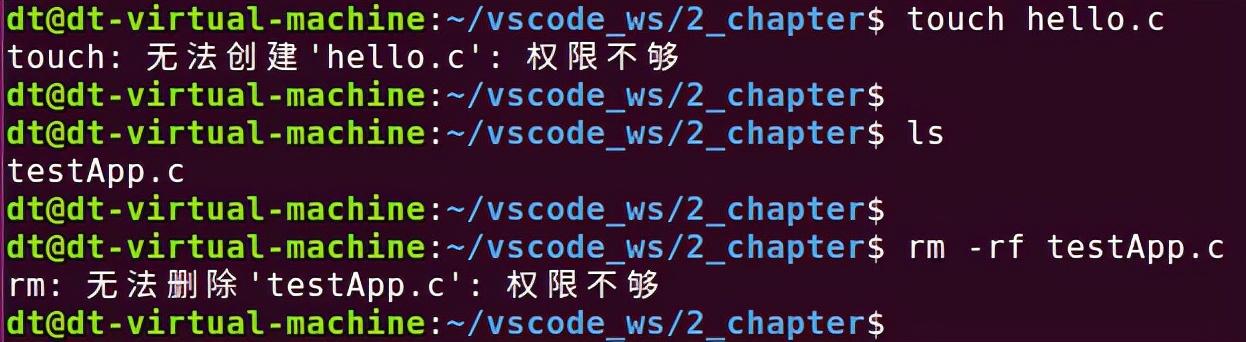
图 5.5.3 创建文件、删除文件
那说明删除文件、创建文件这些操作也是需要相应权限的,那这些权限又是从哪里获取的呢?答案就是目录。目录(文件夹)在Linux系统下也是一种文件,拥有与普通文件相同的权限方案(S/U/G/O),只是这些权限的含义另有所指。
目录的读权限:可列出(譬如:通过ls命令)目录之下的内容(即目录下有哪些文件)。目录的写权限:可以在目录下创建文件、删除文件。目录的执行权限:可访问目录下的文件,譬如对目录下的文件进行读、写、执行等操作。
拥有对目录的读权限,用户只能查看目录中的文件列表,譬如使用ls命令进行查看:
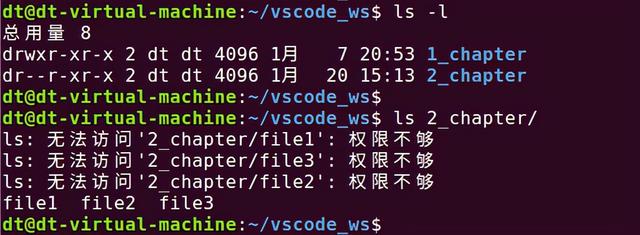
图 5.5.4 只有读权限查看目录下的文件
通过"ls -l"命令可以查看到2_chapter目录对于文件所有者只有读权限,当前操作的用户正是该目录所有者dt,之后通过"ls 2_chapter"命令查看该目录下的文件,确实获取到了该目录下的3个文件:file1、file2、file3,说明只有读权限时,可以查看到目录下有哪些文件、显示出文件的名称;但是会看到上面打印出了一些"权限不够"信息,这是因为Ubuntu发行版对ls命令做了别名处理,执行ls命令的时候携带了一些选项,而这些选项会访问文件的一些信息,所以导致出现"权限不够"问题,这也说明,只拥有读权限、是没法访问目录下的文件的;为了确保使用的是ls命令本身,执行时需要给出路径的完整路径/bin/ls:

图 5.5.5 使用/bin/ls再次执行
要想访问目录下的文件,譬如查看文件的inode节点、大小、权限等信息,还需要对目录拥有执行权限。
反之,若拥有对目录的执行权限、而无读权限,只要知道目录内文件的名称,仍可对其进行访问,但不能列出目录下的内容(即目录下包含的其它文件的名称)。
要想在目录下创建文件或删除原有文件,需要同时拥有对该目录的执行和写权限。
所以由此可知,如果需要对文件进行读、写或执行等操作,不光是需要拥有该文件本身的读、写或执行权限,还需要拥有文件所在目录的执行权限。
检查文件权限access
通过前面的介绍,大家应该知道了,文件的权限检查不单单只讨论文件本身的权限,还需要涉及到文件所在目录的权限,只有同时都满足了,才能通过操作系统的权限检查,进而才可以对文件进行相关操作;所以,程序当中对文件进行相关操作之前,需要先检查执行进程的用户是否对该文件拥有相应的权限。那如何检查呢?可以使用access系统调用,函数原型如下:
#include <unistd.h>
int access(const char *pathname, int mode);
首先,使用该函数需要包含头文件<unistd.h>。
函数参数和返回值含义如下:
pathname:需要进行权限检查的文件路径。
mode:该参数可以取以下值:
F_OK:检查文件是否存在R_OK:检查是否拥有读权限W_OK:检查是否拥有写权限X_OK:检查是否拥有执行权限
除了可以单独使用之外,还可以通过按位或运算符" | "组合在一起。
返回值:检查项通过则返回0,表示拥有相应的权限并且文件存在;否则返回-1,如果多个检查项组合在一起,只要其中任何一项不通过都会返回-1。
测试
通过access函数检查文件是否存在,若存在、则继续检查执行进程的用户对该文件是否有读、写、执行权限。
示例代码 5.5.1 access函数使用示例
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#define MY_FILE "./test_file"
int main(void)
{
int ret;
/* 检查文件是否存在 */
ret = access(MY_FILE, F_OK);
if(-1== ret){
printf("%: file does not exist.\n", MY_FILE);
exit(-1);
}
/* 检查权限 */
ret = access(MY_FILE, R_OK);
if(!ret)
printf("Read permission: Yes\n");
else
printf("Read permission: NO\n");
ret = access(MY_FILE, W_OK);
if(!ret)
printf("Write permission: Yes\n");
else
printf("Write permission: NO\n");
ret = access(MY_FILE, X_OK);
if(!ret)
printf("Execution permission: Yes\n");
else
printf("Execution permission: NO\n");
exit(0);
}
接下来编译测试:
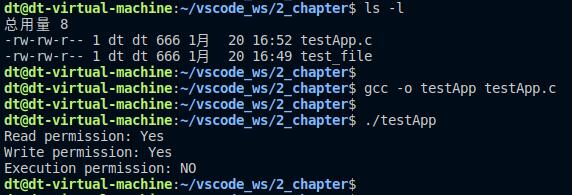
图 5.5.6 access测试结果
修改文件权限chmod
在Linux系统下,可以使用chmod命令修改文件权限,该命令内部实现方法其实是调用了chmod函数,chmod函数是一个系统调用,函数原型如下所示(可通过"man 2 chmod"命令查看):
#include <sys/stat.h>
int chmod(const char *pathname, mode_t mode);
首先,使用该函数需要包含头文件<sys/stat.h>。
函数参数及返回值如下所示:
pathname:需要进行权限修改的文件路径,若该参数所指为符号链接,实际改变权限的文件是符号链接所指向的文件,而不是符号链接文件本身。
mode:该参数用于描述文件权限,与open函数的第三个参数一样,这里不再重述,可以直接使用八进制数据来描述,也可以使用相应的权限宏(单个或通过位或运算符" | "组合)。
返回值:成功返回0;失败返回-1,并设置errno。
文件权限对于文件来说是非常重要的属性,是不能随随便便被任何用户所修改的,要想更改文件权限,要么是超级用户(root)进程、要么进程有效用户ID与文件的用户ID(文件所有者)相匹配。
fchmod函数
该函数功能与chmod一样,参数略有不同。fchmod()与chmod()的区别在于使用了文件描述符来代替文件路径,就像是fstat与stat的区别。函数原型如下所示:
#include <sys/stat.h>
int fchmod(int fd, mode_t mode);
使用了文件描述符fd代替了文件路径pathname,其它功能都是一样的。
测试
示例代码 5.5.2 chmod函数使用示例
#include <sys/stat.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int ret;
ret = chmod("./test_file",0777);
if(-1== ret){
perror("chmod error");
exit(-1);
}
exit(0);
}
上述代码中,通过调用chmod函数将当前目录下的test_file文件,其权限修改为0777(八进制表示方式,也可以使用S_IRUSR、S_IWUSR等这些宏来表示),也就是文件所有者、文件所属组用户以及其它用户都拥有读、写、执行权限,接下来编译测试:
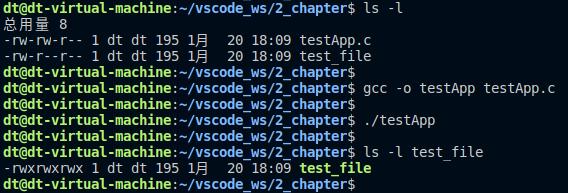
图 5.5.7 chmod函数测试结果
执行程序之前,test_file文件的权限为rw-r--r--(0644),程序执行完成之后,再次查看文件权限为rwxrwxrwx(0777),修改成功!
umask函数
在Linux下有一个umask命令,在Ubuntu系统下执行看看:

图 5.5.8 运行umask命令
可以看到该命令打印出了"0002",这数字表示什么意思呢?这就要从umask命令的作用说起了,umask命令用于查看/设置权限掩码,权限掩码主要用于对新建文件的权限进行屏蔽。权限掩码的表示方式与文件权限的表示方式相同,但是需要去除特殊权限位,umask不能对特殊权限位进行屏蔽。
当新建文件时,文件实际的权限并不等于我们所设置的权限,譬如:调用open函数新建文件时,文件实际的权限并不等于mode参数所描述的权限,而是通过如下关系得到实际权限:
mode & ~umask
譬如调用open函数新建文件时,mode参数指定为0777,假设umask为0002,那么实际权限为:
0777 & (~0002) = 0775
前面给大家介绍open函数的mode参数时,并未向大家提及到umask,所以这里重新向大家说明。
umask权限掩码是进程的一种属性,用于指明该进程新建文件或目录时,应屏蔽哪些权限位。进程的umask通常继承至其父进程(关于父、子进程相关的内容将会在后面章节给大家介绍),譬如在Ubuntu shell终端下执行的应用程序,它的umask继承至该shell进程。
当然,Linux系统提供了umask函数用于设置进程的权限掩码,该函数是一个系统调用,函数原型如下所示(可通过"man 2 umask"命令查看):
#include <sys/types.h>
#include <sys/stat.h>
mode_t umask(mode_t mask);
首先,使用该命令需要包含头文件<sys/types.h>和<sys/stat.h>。
函数参数和返回值含义如下:
mask:需要设置的权限掩码值,可以发现make参数的类型与open函数、chmod函数中的mode参数对应的类型一样,所以其表示方式也是一样的,前面也给大家介绍了,既可以使用数字表示(譬如八进制数)也可以直接使用宏(S_IRUSR、S_IWUSR等)。
返回值:返回设置之前的umask值,也就是旧的umask。
测试
接下来我们编写一个测试代码,使用umask()函数修改进程的umask权限掩码,测试代码如下所示:
示例代码 5.5.3 umask函数使用示例
#include <sys/types.h>
#include <sys/stat.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
mode_t old_mask;
old_mask = umask(0003);
printf("old mask: %04o\n", old_mask);
exit(0);
}
上述代码中,使用umask函数将该进程的umask设置为0003(八进制),返回得到的old_mask则是设置之前旧的umask值,然后将其打印出来:
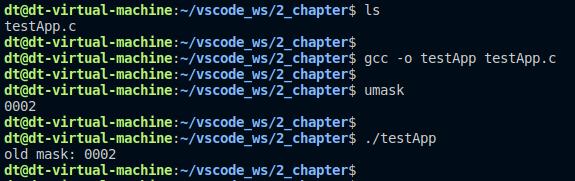
图 5.5.9 umask函数测试结果
从打印信息可以看出,旧的umask等于0002,这个umask是从当前vscode的shell终端继承下来的,如果没有修改进程的umask值,默认就是从父进程继承下来的umask。
这里再次强调,umask是进程自身的一种属性、A进程的umask与B进程的umask无关(父子进程关系除外)。在shell终端下可以使用umask命令设置shell终端的umask值,但是该shell终端关闭之后、再次打开一个终端,新打开的终端将与之前关闭的终端并无任何瓜葛!
文件的时间属性
前面给大家介绍了3个文件的时间属性:文件最后被访问的时间、文件内容最后被修改的时间以及文件状态最后被改变的时间,分别记录在struct stat结构体的st_atim、st_mtim以及st_ctim变量中,如下所示:
字段
| 说明
|
st_atim
|
文件最后被访问的时间
|
st_mtim
|
文件内容最后被修改的时间
|
st_ctim
|
文件状态最后被改变的时间
|
表 5.6.1 与文件相关的3个时间属性
文件最后被访问的时间:访问指的是读取文件内容,文件内容最后一次被读取的时间,譬如使用read()函数读取文件内容便会改变该时间属性;文件内容最后被修改的时间:文件内容发生改变,譬如使用write()函数写入数据到文件中便会改变该时间属性;文件状态最后被改变的时间:状态更改指的是该文件的inode节点最后一次被修改的时间,譬如更改文件的访问权限、更改文件的用户ID、用户组ID、更改链接数等,但它们并没有更改文件的实际内容,也没有访问(读取)文件内容。为什么文件状态的更改指的是inode节点的更改呢?3.1小节给大家介绍inode节点的时候给大家介绍过,inode中包含了很多文件信息,譬如:文件字节大小、文件所有者、文件对应的读/写/执行权限、文件时间戳(时间属性)、文件数据存储的block(块)等,所以由此可知,状态的更改指的就是inode节点内容的更改。譬如chmod()、chown()等这些函数都能改变该时间属性。
表 5.6.2列出了一些系统调用或C库函数对文件时间属性的影响,有些操作并不仅仅只会影响文件本身的时间属性,还会影响到其父目录的相关时间属性。
函数
| 文件
| 父目录
| 注释
| a
| m
| c
| a
| m
| c
|
chmod()
chown()
exec()
link()
mkdir()
mkfifo()
mknod()
open()
read()
rename()
rmdir()
unlink()
utime()
write()
| *
*
*
*
*
*
*
| *
*
*
*
*
*
| *
*
*
*
*
*
*
*
*
*
*
|
| *
*
*
*
*
*
*
*
| *
*
*
*
*
*
*
*
| 与fchmod()相同
与fchown()和lchown()相同
影响第二个参数的父目录
新建文件时
与pread()相同
与remove()相同
与utimes()、futimesat()相同
与pwrite()相同
|
表 5.6.2 不同函数对文件时间属性的影响
utime()、utimes()修改时间属性
文件的时间属性虽然会在我们对文件进行相关操作(譬如:读、写)的时候发生改变,但这些改变都是隐式、被动的发生改变,除此之外,还可以使用Linux系统提供的系统调用显式的修改文件的时间属性。本小节给大家介绍如何使用utime()和utimes()函数来修改文件的时间属性。
Tips:只能显式修改文件的最后一次访问时间和文件内容最后被修改的时间,不能显式修改文件状态最后被改变的时间,大家可以想一想为什么?笔者把这个作为思考题留给大家!
utime()函数
utime()函数原型如下所示:
#include <sys/types.h>
#include <utime.h>
int utime(const char *filename, const struct utimbuf *times);
首先,使用该函数需要包含头文件<sys/types.h>和<utime.h>。
函数参数和返回值含义如下:
filename:需要修改时间属性的文件路径。
times:将时间属性修改为该参数所指定的时间值,times是一个struct utimbuf结构体类型的指针,稍后给大家介绍,如果将times参数设置为NULL,则会将文件的访问时间和修改时间设置为系统当前时间。
返回值:成功返回值0;失败将返回-1,并会设置errno。
来看看struct utimbuf结构体:
示例代码 5.6.1 struct utimbuf结构体
struct utimbuf {
time_t actime; /* 访问时间 */
time_t modtime; /* 内容修改时间 */
};
该结构体中包含了两个time_t类型的成员,分别用于表示访问时间和内容修改时间,time_t类型其实就是long int类型,所以这两个时间是以秒为单位的,所以由此可知,utime()函数设置文件的时间属性精度只能到秒。
同样对于文件来说,时间属性也是文件非常重要的属性之一,对文件时间属性的修改也不是任何用户都可以随便修改的,只有以下两种进程可对其进行修改:
超级用户进程(以root身份运行的进程)。有效用户ID与该文件用户ID(文件所有者)相匹配的进程。在参数times等于NULL的情况下,对文件拥有写权限的进程。
除以上三种情况之外的用户进程将无法对文件时间戳进行修改。
utime测试
接下来我们编写一个简单地测试程序,使用utime()函数修改文件的访问时间和内容修改时间,示例代码如下:
示例代码 5.6.2 utime函数使用示例
#include <sys/types.h>
#include <utime.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MY_FILE "./test_file"
int main(void)
{
struct utimbuf utm_buf;
time_t cur_sec;
int ret;
/* 检查文件是否存在 */
ret = access(MY_FILE, F_OK);
if(-1== ret){
printf("Error: %s file does not exist!\n", MY_FILE);
exit(-1);
}
/* 获取当前时间 */
time(&cur_sec);
utm_buf.actime = cur_sec;
utm_buf.modtime = cur_sec;
/* 修改文件时间戳 */
ret = utime(MY_FILE,&utm_buf);
if(-1== ret){
perror("utime error");
exit(-1);
}
exit(0);
}
上述代码尝试将test_file文件的访问时间和内容修改时间修改为当前系统时间。程序中使用到了time()函数,time()是Linux系统调用,用于获取当前时间(也可以直接将times参数设置为NULL,这样就不需要使用time函数来获取当前时间了),单位为秒,关于该函数在后面的章节内容中会给大家介绍,这里简单地了解一下。接下来编译测试,在运行程序之间,先使用stat命令查看test_file文件的时间戳,如下:
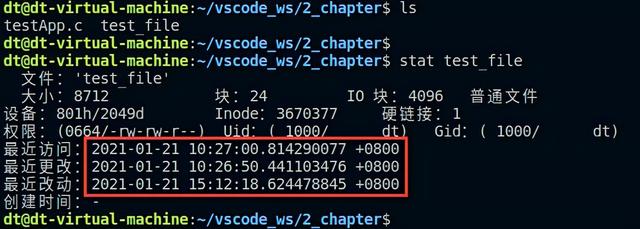
图 5.6.1 查看test_file文件的时间戳
接下来编译程序、运行测试:
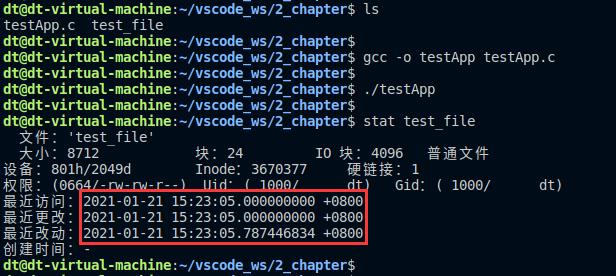
图 5.6.2 运行测试程序
会发现执行完测试程序之后,test_file文件的访问时间和内容修改时间均被更改为当前时间了(大家可以使用date命令查看当前系统时间),并且会发现状态更改时间也会修改为当前时间了,当然这个不是在程序中修改、而是内核帮它自动修改的,为什么会这样呢?如果大家理解了之前介绍的知识内容,完全可以理解这个问题,这里笔者不再重述!
utimes()函数
utimes()也是系统调用,功能与utime()函数一致,只是参数、细节上有些许不同,utimes()与utime()最大的区别在于前者可以以微秒级精度来指定时间值,其函数原型如下所示:
#include <sys/time.h>
int utimes(const char *filename, const struct timeval times[2]);
首先,使用该函数需要包含头文件<sys/time.h>。
函数参数和返回值含义如下:
filename:需要修改时间属性的文件路径。
times:将时间属性修改为该参数所指定的时间值,times是一个struct timeval结构体类型的数组,数组共有两个元素,第一个元素用于指定访问时间,第二个元素用于指定内容修改时间,稍后给大家介绍,如果times参数为NULL,则会将文件的访问时间和修改时间设置为当前时间。
返回值:成功返回0;失败返回-1,并且会设置errno。
来看看struct timeval结构体:
示例代码 5.6.3 struct timeval结构体
struct timeval {
long tv_sec;/* 秒 */
long tv_usec;/* 微秒 */
};
该结构体包含了两个成员变量tv_sec和tv_usec,分别用于表示秒和微秒。
utimes()遵循与utime()相同的时间戳修改权限规则。
utimes测试
示例代码 5.6.4 utimes使用示例
#include <unistd.h>
#include <time.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#define MY_FILE "./test_file"
int main(void)
{
struct timeval tmval_arr[2];
time_t cur_sec;
int ret;
int i;
/* 检查文件是否存在 */
ret = access(MY_FILE, F_OK);
if(-1== ret){
printf("Error: %s file does not exist!\n", MY_FILE);
exit(-1);
}
/* 获取当前时间 */
time(&cur_sec);
for(i =0; i <2; i++){
tmval_arr[i].tv_sec = cur_sec;
tmval_arr[i].tv_usec =0;
}
/* 修改文件时间戳 */
ret = utimes(MY_FILE, tmval_arr);
if(-1== ret){
perror("utimes error");
exit(-1);
}
exit(0);
}
代码不再给大家进行介绍了,功能与示例代码 5.6.2相同,大家可以自己动手编译、运行测试。
futimens()、utimensat()修改时间属性
除了上面给大家介绍了两个系统调用外,这里再向大家介绍两个系统调用,功能与utime()和utimes()函数功能一样,用于显式修改文件时间戳,它们是futimens()和utimensat()。
这两个系统调用相对于utime和utimes函数有以下三个优点:
可按纳秒级精度设置时间戳。相对于提供微秒级精度的utimes(),这是重大改进!可单独设置某一时间戳。譬如,只设置访问时间、而修改时间保持不变,如果要使用utime()或utimes()来实现此功能,则需要首先使用stat()获取另一个时间戳的值,然后再将获取值与打算变更的时间戳一同指定。可独立将任一时间戳设置为当前时间。使用utime()或utimes()函数虽然也可以通过将times参数设置为NULL来达到将时间戳设置为当前时间的效果,但是不能单独指定某一个时间戳,必须全部设置为当前时间(不考虑使用额外函数获取当前时间的方式,譬如time())。
futimens()函数
futimens函数原型如下所示(可通过"man 2 utimensat"命令查看):
#include <fcntl.h>
#include <sys/stat.h>
int futimens(int fd, const struct timespec times[2]);
函数原型和返回值含义如下:
fd:文件描述符。
times:将时间属性修改为该参数所指定的时间值,times指向拥有2个struct timespec结构体类型变量的数组,数组共有两个元素,第一个元素用于指定访问时间,第二个元素用于指定内容修改时间,该结构体在5.2.3小节给大家介绍过了,这里不再重述!
返回值:成功返回0;失败将返回-1,并设置errno。
所以由此可知,使用futimens()设置文件时间戳,需要先打开文件获取到文件描述符。
该函数的时间戳可以按下列4种方式之一进行指定:
如果times参数是一个空指针,也就是NULL,则表示将访问时间和修改时间都设置为当前时间。如果times参数指向两个struct timespec结构体类型变量的数组,任一数组元素的tv_nsec字段的值设置为UTIME_NOW,则表示相应的时间戳设置为当前时间,此时忽略相应的tv_sec字段。如果times参数指向两个struct timespec结构体类型变量的数组,任一数组元素的tv_nsec字段的值设置为UTIME_OMIT,则表示相应的时间戳保持不变,此时忽略tv_sec字段。如果times参数指向两个struct timespec结构体类型变量的数组,且tv_nsec字段的值既不是UTIME_NOW也不是UTIME_OMIT,在这种情况下,相应的时间戳设置为相应的tv_sec和tv_nsec字段指定的值。
Tips:UTIME_NOW和UTIME_OMIT是两个宏定义。
使用futimens()函数只有以下进程,可对文件时间戳进行修改:
超级用户进程。在参数times等于NULL的情况下,对文件拥有写权限的进程。有效用户ID与该文件用户ID(文件所有者)相匹配的进程。
futimens()测试
示例代码 5.6.5 futimens函数使用示例
#include <fcntl.h>
#include <sys/stat.h>
#include <unistd.h>
#include <sys/types.h>
#include <time.h>
#include <stdio.h>
#include <stdlib.h>
#define MY_FILE "./test_file"
int main(void)
{
struct timespec tmsp_arr[2];
int ret;
int fd;
/* 检查文件是否存在 */
ret = access(MY_FILE, F_OK);
if(-1== ret){
printf("Error: %s file does not exist!\n", MY_FILE);
exit(-1);
}
/* 打开文件 */
fd = open(MY_FILE, O_RDONLY);
if(-1== fd){
perror("open error");
exit(-1);
}
/* 修改文件时间戳 */
#if 1
ret = futimens(fd,NULL);//同时设置为当前时间
#endif
#if 0
tmsp_arr[0].tv_nsec = UTIME_OMIT;//访问时间保持不变
tmsp_arr[1].tv_nsec = UTIME_NOW;//内容修改时间设置为当期时间
ret = futimens(fd, tmsp_arr);
#endif
#if 0
tmsp_arr[0].tv_nsec = UTIME_NOW;//访问时间设置为当前时间
tmsp_arr[1].tv_nsec = UTIME_OMIT;//内容修改时间保持不变
ret = futimens(fd, tmsp_arr);
#endif
if(-1== ret){
perror("futimens error");
goto err;
}
err:
close(fd);
exit(ret);
}
代码不再给大家进行介绍,大家可以自己动手编译、运行测试。
utimensat()函数
utimensat()与futimens()函数在功能上是一样的,同样可以实现纳秒级精度设置时间戳、单独设置某一时间戳、独立将任一时间戳设置为当前时间,与futimens()在参数以及细节上存在一些差异,使用futimens()函数,需要先将文件打开,通过文件描述符进行操作,utimensat()可以直接使用文件路径方式进行操作。utimensat函数原型如下所示:
#include <fcntl.h>
#include <sys/stat.h>
int utimensat(int dirfd, const char *pathname, const struct timespec times[2], int flags);
首先,使用该函数需要包含头文件<fcntl.h>和<sys/stat.h>。
函数参数和返回值含义如下:
dirfd:该参数可以是一个目录的文件描述符,也可以是特殊值AT_FDCWD;如果pathname参数指定的是文件的绝对路径,则此参数会被忽略。
pathname:指定文件路径。如果pathname参数指定的是一个相对路径、并且dirfd参数不等于特殊值AT_FDCWD,则实际操作的文件路径是相对于文件描述符dirfd指向的目录进行解析。如果pathname参数指定的是一个相对路径、并且dirfd参数等于特殊值AT_FDCWD,则实际操作的文件路径是相对于调用进程的当前工作目录进行解析,关于进程的工作目录在5.7小节中有介绍。
times:与futimens()的times参数含义相同。
flags:此参数可以为0,也可以设置为AT_SYMLINK_NOFOLLOW,如果设置为AT_SYMLINK_NOFOLLOW,当pathname参数指定的文件是符号链接,则修改的是该符号链接的时间戳,而不是它所指向的文件。
返回值:成功返回0;失败返回-1、并会设置时间戳。
utimensat()遵循与futimens()相同的时间戳修改权限规则。
utimensat()函数测试
示例代码 5.6.6 utimensat函数使用示例
#include <fcntl.h>
#include <sys/stat.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#define MY_FILE "/home/dt/vscode_ws/2_chapter/test_file"
int main(void)
{
struct timespec tmsp_arr[2];
int ret;
/* 检查文件是否存在 */
ret = access(MY_FILE, F_OK);
if(-1== ret){
printf("Error: %s file does not exist!\n", MY_FILE);
exit(-1);
}
/* 修改文件时间戳 */
#if 1
ret = utimensat(-1, MY_FILE,NULL, AT_SYMLINK_NOFOLLOW);//同时设置为当前时间
#endif
#if 0
tmsp_arr[0].tv_nsec = UTIME_OMIT;//访问时间保持不变
tmsp_arr[1].tv_nsec = UTIME_NOW;//内容修改时间设置为当期时间
ret = utimensat(-1, MY_FILE, tmsp_arr, AT_SYMLINK_NOFOLLOW);
#endif
#if 0
tmsp_arr[0].tv_nsec = UTIME_NOW;//访问时间设置为当前时间
tmsp_arr[1].tv_nsec = UTIME_OMIT;//内容修改时间保持不变
ret = utimensat(-1, MY_FILE, tmsp_arr, AT_SYMLINK_NOFOLLOW);
#endif
if(-1== ret){
perror("futimens error");
exit(-1);
}
exit(0);
}
代码不再给大家进行介绍,大家可以自己动手编译、运行测试。
符号链接(软链接)与硬链接
在Linux系统中有两种链接文件,分为软链接(也叫符号链接)文件和硬链接文件,软链接文件也就是前面给大家的Linux系统下的七种文件类型之一,其作用类似于Windows下的快捷方式。那么硬链接文件又是什么呢?本小节就来聊一聊它们之间的区别。
首先,从使用角度来讲,两者没有任何区别,都与正常的文件访问方式一样,支持读、写以及执行。那它们的区别在哪呢?在底层原理上,为了说明这个问题,先来创建一个硬链接文件,如下所示:
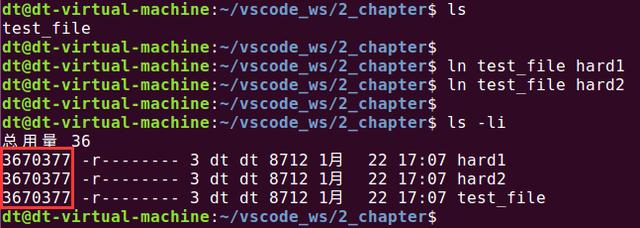
图 5.7.1 创建硬链接文件
Tips:使用ln命令可以为一个文件创建软链接文件或硬链接文件,用法如下:
硬链接:ln 源文件 链接文件
软链接:ln -s 源文件 链接文件
关于该命令其它用法,可以查看man手册。
从图 5.7.1中可知,使用ln命令创建的两个硬链接文件与源文件test_file都拥有相同的inode号,既然inode相同,也就意味着它们指向了物理硬盘的同一个区块,仅仅只是文件名字不同而已,创建出来的硬链接文件与源文件对文件系统来说是完全平等的关系。那么大家可能要问了,如果删除了硬链接文件或源文件其中之一,那文件所对应的inode以及文件内容在磁盘中的数据块会被文件系统回收吗?事实上并不会这样,因为inode数据结结构中会记录文件的链接数,这个链接数指的就是硬链接数,struct stat结构体中的st_nlink成员变量就记录了文件的链接数,这些内容前面已经给大家介绍过了。
当为文件每创建一个硬链接,inode节点上的链接数就会加一,每删除一个硬链接,inode节点上的链接数就会减一,直到为0,inode节点和对应的数据块才会被文件系统所回收,也就意味着文件已经从文件系统中被删除了。从图 5.7.1中可知,使用"ls -li"命令查看到,此时链接数为3(dt用户名前面的那个数字),我们明明创建了2个链接文件,为什么链接数会是3?其实源文件test_file本身就是一个硬链接文件,所以这里才是3。
当我们删除其中任何一个文件后,链接数就会减少,如下所示:
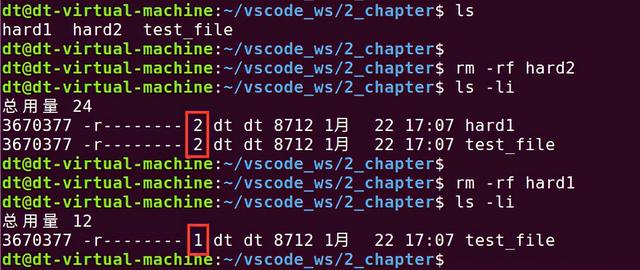
图 5.7.2 删除链接文件
接下来再来聊一聊软链接文件,软链接文件与源文件有着不同的inode号,如图 5.7.3所示,所以也就是意味着它们之间有着不同的数据块,但是软链接文件的数据块中存储的是源文件的路径名,链接文件可以通过这个路径找到被链接的源文件,它们之间类似于一种“主从”关系,当源文件被删除之后,软链接文件依然存在,但此时它指向的是一个无效的文件路径,这种链接文件被称为悬空链接,如图 5.7.4所示。
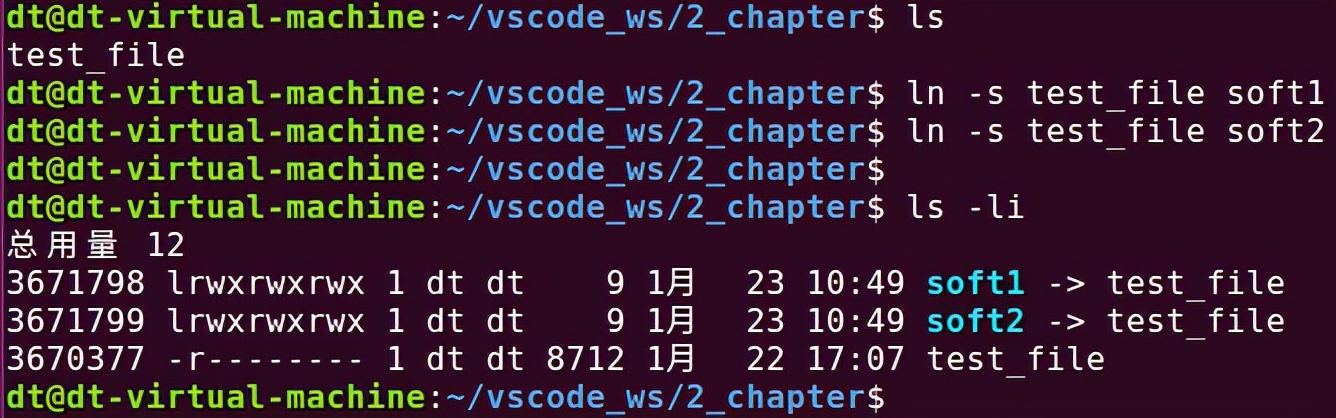
图 5.7.3 创建软链接
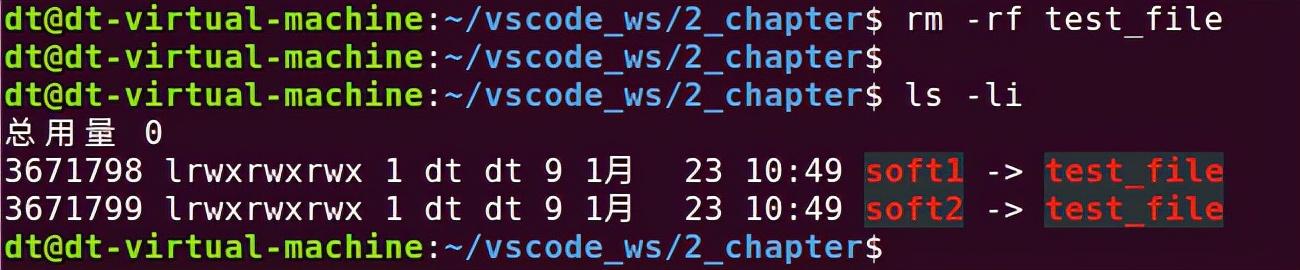
图 5.7.4 删除源文件
从图中还可看出,inode节点中记录的链接数并未将软链接计算在内。
介绍完它们之间的区别之后,大家可能觉得硬链接相对于软链接来说有较大的优势,其实并不是这样,对于硬链接来说,存在一些限制情况,如下:
不能对目录创建硬链接(超级用户可以创建,但必须在底层文件系统支持的情况下)。硬链接通常要求链接文件和源文件位于同一文件系统中。
而软链接文件的使用并没有上述限制条件,优点如下所示:
可以对目录创建软链接;可以跨越不同文件系统;可以对不存在的文件创建软链接。
创建链接文件
在Linux系统下,可以使用系统调用创建硬链接文件或软链接文件,本小节向大家介绍如何通过这些系统调用创建链接文件。
创建硬链接link()
link()系统调用用于创建硬链接文件,函数原型如下(可通过"man 2 link"命令查看):
#include <unistd.h>
int link(const char *oldpath, const char *newpath);
首先,使用该函数需要包含头文件<unistd.h>。
函数原型和返回值含义如下:
oldpath:用于指定被链接的源文件路径,应避免oldpath参数指定为软链接文件,为软链接文件创建硬链接没有意义,虽然并不会报错。
newpath:用于指定硬链接文件路径,如果newpath指定的文件路径已存在,则会产生错误。
返回值:成功返回0;失败将返回-1,并且会设置errno。
link函数测试
接下来我们编写一个简单地程序,演示link函数如何使用:
示例代码 5.7.1 link函数使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
int ret;
ret = link("./test_file","./hard");
if(-1== ret){
perror("link error");
exit(-1);
}
exit(0);
}
程序中通过link函数为当前目录下的test_file文件创建了一个硬链接hard,编译测试:
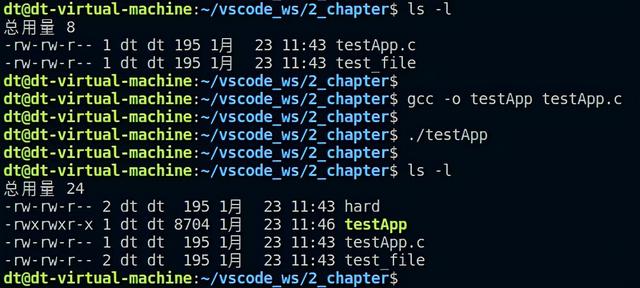
图 5.7.5 link函数测试结果
创建软链接symlink()
symlink()系统调用用于创建软链接文件,函数原型如下(可通过"man 2 symlink"命令查看):
#include <unistd.h>
int symlink(const char *target, const char *linkpath);
首先,使用该函数需要包含头文件<unistd.h>。
函数参数和返回值含义如下:
target:用于指定被链接的源文件路径,target参数指定的也可以是一个软链接文件。
linkpath:用于指定硬链接文件路径,如果newpath指定的文件路径已存在,则会产生错误。
返回值:成功返回0;失败将返回-1,并会设置errno。
创建软链接时,并不要求target参数指定的文件路径已经存在,如果文件不存在,那么创建的软链接将成为“悬空链接”。
symlink函数测试
接下来我们编写一个简单地程序,演示symlink函数如何使用:
示例代码 5.7.2 symlink函数使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
int ret;
ret = symlink("./test_file","./soft");
if(-1== ret){
perror("symlink error");
exit(-1);
}
exit(0);
}
程序中通过symlink函数为当前目录下的test_file文件创建了一个软链接soft,编译测试:
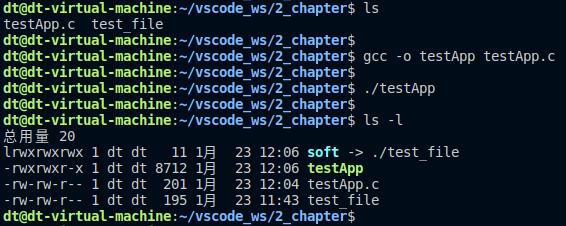
图 5.7.6 symlink函数测试结果
读取软链接文件
前面给大家介绍到,软链接文件数据块中存储的是被链接文件的路径信息,那如何读取出软链接文件中存储的路径信息呢?大家认为使用read函数可以吗?答案是不可以,因为使用read函数之前,需要先open打开该文件得到文件描述符,但是调用open打开一个链接文件本身是不会成功的,因为打开的并不是链接文件本身、而是其指向的文件,所以不能使用read来读取,那怎么办呢?可以使用系统调用readlink。
readlink函数原型如下所示:
#include <unistd.h>
ssize_t readlink(const char *pathname, char *buf, size_t bufsiz);
函数参数和返回值含义如下:
pathname:需要读取的软链接文件路径。只能是软链接文件路径,不能是其它类型文件,否则调用函数将报错。
buf:用于存放路径信息的缓冲区。
bufsiz:读取大小,一般读取的大小需要大于链接文件数据块中存储的文件路径信息字节大小。
返回值:失败将返回-1,并会设置errno;成功将返回读取到的字节数。
readlink函数测试
接下来我们编写一个简单地程序,演示readlink函数如何使用:
示例代码 5.7.3 readlink函数使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main(void)
{
char buf[50];
int ret;
memset(buf,0x0,sizeof(buf));
ret = readlink("./soft", buf,sizeof(buf));
if(-1== ret){
perror("readlink error");
exit(-1);
}
printf("%s\n", buf);
exit(0);
}
使用readlink函数读取当前目录下的软链接文件soft,并将读取到的信息打印出来,测试如下:
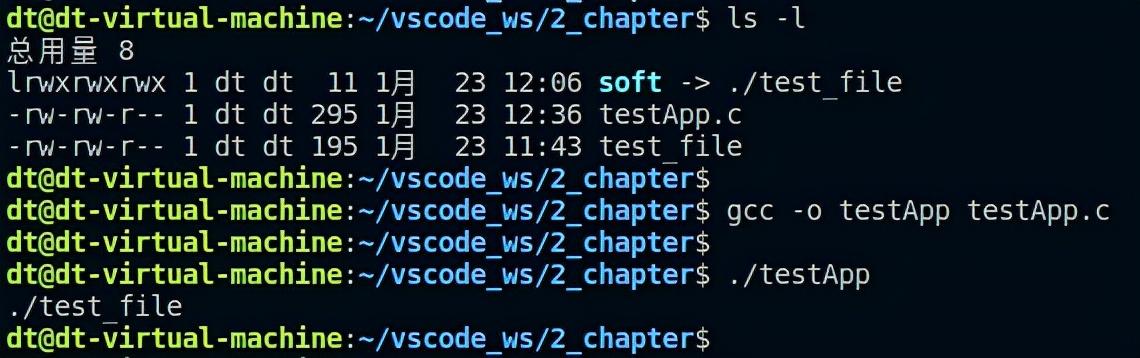
图 5.7.7 readlink函数测试结果
目录
目录(文件夹)在Linux系统也是一种文件,是一种特殊文件,同样可以使用前面给大家介绍open、read等这些系统调用以及C库函数对其进行操作,但是目录作为一种特殊文件,并不适合使用前面介绍的文件I/O方式进行读写等操作。在Linux系统下,会有一些专门的系统调用或C库函数用于对文件夹进行操作,譬如:打开、创建文件夹、删除文件夹、读取文件夹以及遍历文件夹中的文件等,那么本小节将向大家介绍目录相关的知识内容。
目录存储形式
3.1小节中给大家介绍了普通文件的管理形式或存储形式,本小节聊一聊目录这种特殊文件在文件系统中的存储形式,其实目录在文件系统中的存储方式与常规文件类似,常规文件包括了inode节点以及文件内容数据存储块(block),参考图 3.1.1所示;但对于目录来说,其存储形式则是由inode节点和目录块所构成,目录块当中记录了有哪些文件组织在这个目录下,记录它们的文件名以及对应的inode编号。
其存储形式如下图所示:
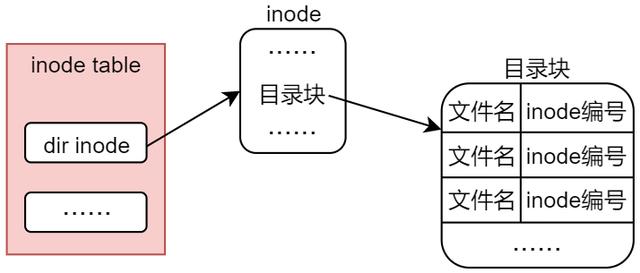
图 5.8.1 目录在文件系统中的存储形式
目录块当中有多个目录项(或叫目录条目),每一个目录项(或目录条目)都会对应到该目录下的某一个文件,目录项当中记录了该文件的文件名以及它的inode节点编号,所以通过目录的目录块便可以遍历找到该目录下的所有文件以及所对应的inode节点。
所以对此总结如下:
普通文件由inode节点和数据块构成目录由inode节点和目录块构成
创建和删除目录
使用open函数可以创建一个普通文件,但不能用于创建目录文件,在Linux系统下,提供了专门用于创建目录mkdir()以及删除目录rmdir相关的系统调用。
mkdir函数
函数原型如下所示:
#include <sys/stat.h>
#include <sys/types.h>
int mkdir(const char *pathname, mode_t mode);
函数参数和返回值含义如下:
pathname:需要创建的目录路径。
mode:新建目录的权限设置,设置方式与open函数的mode参数一样,最终权限为(mode & ~umask)。
返回值:成功返回0;失败将返回-1,并会设置errno。
pathname参数指定的新建目录的路径,该路径名可以是相对路径,也可以是绝对路径,若指定的路径名已经存在,则调用mkdir()将会失败。
mode参数指定了新目录的权限,目录拥有与普通文件相同的权限位,但是其表示的含义与普通文件却有不同,5.5.2小计对此作了说明。
mkdir函数测试
示例代码 5.8.1 mkdir函数使用示例
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/types.h>
int main(void)
{
int ret;
ret = mkdir("./new_dir", S_IRWXU |
S_IRGRP | S_IXGRP |
S_IROTH | S_IXOTH);
if(-1== ret){
perror("mkdir error");
exit(-1);
}
exit(0);
}
上述代码中,我们通过mkdir函数在当前目录下创建了一个目录new_dir,并将其权限设置为0755(八进制),编译运行:
图 5.8.2 mkdir创建目录
rmdir函数
rmdir()用于删除一个目录
#include <unistd.h>
int rmdir(const char *pathname);
首先,使用该函数需要包含头文件<unistd.h>。
函数参数和返回值含义如下:
pathname:需要删除的目录对应的路径名,并且该目录必须是一个空目录,也就是该目录下只有.和..这两个目录项;pathname指定的路径名不能是软链接文件,即使该链接文件指向了一个空目录。
返回值:成功返回0;失败将返回-1,并会设置errno。
rmdir函数测试
示例代码 5.8.2 rmdir函数使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
int ret;
ret = rmdir("./new_dir");
if(-1== ret){
perror("rmdir error");
exit(-1);
}
exit(0);
}
打开、读取以及关闭目录
打开、读取、关闭一个普通文件可以使用open()、read()、close(),而对于目录来说,可以使用opendir()、readdir()和closedir()来打开、读取以及关闭目录,接下来将向大家介绍这3个C库函数的用法。
打开文件opendir
opendir()函数用于打开一个目录,并返回指向该目录的句柄,供后续操作使用。Opendir是一个C库函数,opendir()函数原型如下所示:
#include <sys/types.h>
#include <dirent.h>
DIR *opendir(const char *name);
函数参数和返回值含义如下:
name:指定需要打开的目录路径名,可以是绝对路径,也可以是相对路径。
返回值:成功将返回指向该目录的句柄,一个DIR指针(其实质是一个结构体指针),其作用类似于open函数返回的文件描述符fd,后续对该目录的操作需要使用该DIR指针变量;若调用失败,则返回NULL。
读取目录readdir
readdir()用于读取目录,获取目录下所有文件的名称以及对应inode号。这里给大家介绍的readdir()是一个C库函数(事实上Linux系统还提供了一个readdir系统调用),其函数原型如下所示:
#include <dirent.h>
struct dirent *readdir(DIR *dirp);
首先,使用该函数需要包含头文件<dirent.h>。
函数参数和返回值含义如下:
dirp:目录句柄DIR指针。
返回值:返回一个指向struct dirent结构体的指针,该结构体表示dirp指向的目录流中的下一个目录条目。在到达目录流的末尾或发生错误时,它返回NULL。
Tips:“流”是从自然界中抽象出来的一种概念,有点类似于自然界当中的水流,在文件操作中,文件内容数据类似池塘中存储的水,N个字节数据被读取出来或将N个字节数据写入到文件中,这些数据就构成了字节流。
“流”这个概念是动态的,而不是静态的。编程当中提到这个概念,一般都是与I/O相关,所以也经常叫做I/O流;但对于目录这种特殊文件来说,这里将目录块中存储的数据称为目录流,存储了一个一个的目录项(目录条目)。
struct dirent结构体内容如下所示:
示例代码 5.8.3 struct dirent结构体
struct dirent {
ino_t d_ino;/* inode编号 */
off_t d_off;/* not an offset; see NOTES */
unsignedshort d_reclen;/* length of this record */
unsignedchar d_type;/* type of file; not supported by all filesystem types */
char d_name[256];/* 文件名 */
};
对于struct dirent结构体,我们只需要关注d_ino和d_name两个字段即可,分别记录了文件的inode编号和文件名,其余字段并不是所有系统都支持,所以也不再给大家介绍,这些字段一般也不会使用到。
每调用一次readdir(),就会从drip所指向的目录流中读取下一条目录项(目录条目),并返回struct dirent结构体指针,指向经静态分配而得的struct dirent类型结构,每次调用readdir()都会覆盖该结构。一旦遇到目录结尾或是出错,readdir()将返回NULL,针对后一种情况,还会设置errno以示具体错误。那如何区别究竟是到了目录末尾还是出错了呢,可通过如下代码进行判断:
error = 0;
direntp = readdir(dirp);
if (NULL == direntp) {
if (0 != error) {
/* 出现了错误 */
} else {
/* 已经到了目录末尾 */
}
}
使用readdir()返回时并未对文件名进行排序,而是按照文件在目录中出现的天然次序(这取决于文件系统向目录添加文件时所遵循的次序,及其在删除文件后对目录列表中空隙的填补方式)。
当使用opendir()打开目录时,目录流将指向了目录列表的头部(0),使用readdir()读取一条目录条目之后,目录流将会向后移动、指向下一个目录条目。这其实跟open()类似,当使用open()打开文件的时候,文件位置偏移量默认指向了文件头部,当使用read()或write()进行读写时,文件偏移量会自动向后移动。
rewinddir函数
rewinddir()是C库函数,可将目录流重置为目录起点,以便对readdir()的下一次调用将从目录列表中的第一个文件开始。rewinddir函数原型如下所示:
#include <sys/types.h>
#include <dirent.h>
void rewinddir(DIR *dirp);
首先,使用该函数需要包含头文件<dirent.h>。
函数参数和返回值含义如下:
dirp:目录句柄。
返回值:无返回值。
关闭目录closedir函数
closedir()函数用于关闭处于打开状态的目录,同时释放它所使用的资源,其函数原型如下所示:
#include <sys/types.h>
#include <dirent.h>
int closedir(DIR *dirp);
首先,使用该函数需要包含头文件<sys/types.h>和<dirent.h>。
函数参数和返回值含义如下:
dirp:目录句柄。
返回值:成功返回0;失败将返回-1,并设置errno。
练习
根据本小节所学知识内容,可以做一个简单地编程练习,打开一个目录、并将目录下的所有文件的名称以及其对应inode编号打印出来。示例代码如下所示:
示例代码 5.8.4 本节编程练习
#include <stdio.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <errno.h>
int main(void)
{
struct dirent *dir;
DIR *dirp;
int ret =0;
/* 打开目录 */
dirp = opendir("./my_dir");
if(NULL== dirp){
perror("opendir error");
exit(-1);
}
/* 循环读取目录流中的所有目录条目 */
errno =0;
while(NULL!=(dir = readdir(dirp)))
printf("%s %ld\n", dir->d_name, dir->d_ino);
if(0!= errno){
perror("readdir error");
ret =-1;
goto err;
}else
printf("End of directory!\n");
err:
closedir(dirp);
exit(ret);
}
使用opendir()打开了当前目录下的my_dir目录,该目录下的文件如下所示:
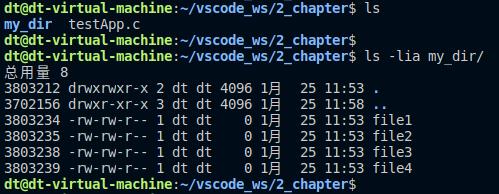
图 5.8.3 my_dir目录下的文件列表
接下来编译、运行:
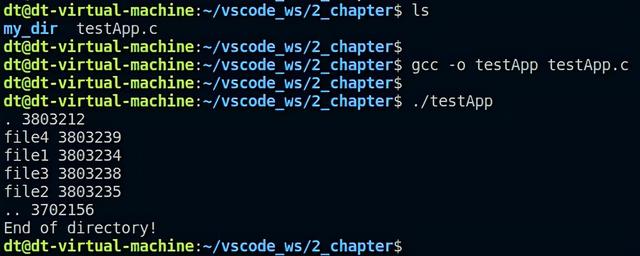
图 5.8.4 运行测试程序
由此可知,示例代码 5.8.4能够将my_dir目录下的所有文件全部扫描出来,打印出它们的名字以及inode节点。
进程的当前工作目录
Linux下的每一个进程都有自己的当前工作目录(current working directory),当前工作目录是该进程解析、搜索相对路径名的起点(不是以" / "斜杆开头的绝对路径)。譬如,代码中调用open函数打开文件时,传入的文件路径使用相对路径方式进行表示,那么该进程解析这个相对路径名时、会以进程的当前工作目录作为参考目录。
一般情况下,运行一个进程时、其父进程的当前工作目录将被该进程所继承,成为该进程的当前工作目录。可通过getcwd函数来获取进程的当前工作目录,如下所示:
#include <unistd.h>
char *getcwd(char *buf, size_t size);
这是一个系统调用,使用该函数之前,需要包含头文件<unistd.h>。
函数参数和返回值含义如下:
buf:getcwd()将内含当前工作目录绝对路径的字符串存放在buf缓冲区中。
size:缓冲区的大小,分配的缓冲区大小必须要大于字符串长度,否则调用将会失败。
返回值:如果调用成功将返回指向buf的指针,失败将返回NULL,并设置errno。
Tips:若传入的buf为NULL,且size为0,则getcwd()内部会按需分配一个缓冲区,并将指向该缓冲区的指针作为函数的返回值,为了避免内存泄漏,调用者使用完之后必须调用free()来释放这一缓冲区所占内存空间。
测试
接下来,我们编写一个简单地测试程序用于读取进程的当前工作目录:
示例代码 5.8.5 getcwd函数测试例程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main(void)
{
char buf[100];
char*ptr;
memset(buf,0x0,sizeof(buf));
ptr = getcwd(buf,sizeof(buf));
if(NULL== ptr){
perror("getcwd error");
exit(-1);
}
printf("Current working directory: %s\n", buf);
exit(0);
}
编译运行:
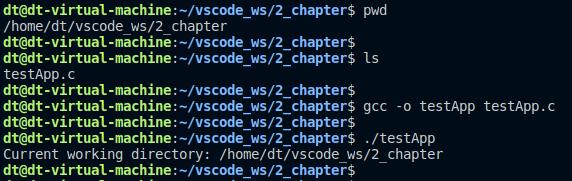
图 5.8.5 测试结果
改变当前工作目录
系统调用chdir()和fchdir()可以用于更改进程的当前工作目录,函数原型如下所示:
#include <unistd.h>
int chdir(const char *path);
int fchdir(int fd);
首先,使用这两个函数之一需要包含头文件<unistd.h>。
函数参数和返回值含义如下:
path:将进程的当前工作目录更改为path参数指定的目录,可以是绝对路径、也可以是相对路径,指定的目录必须要存在,否则会报错。
fd:将进程的当前工作目录更改为fd文件描述符所指定的目录(譬如使用open函数打开一个目录)。
返回值:成功均返回0;失败均返回-1,并设置errno。
此两函数的区别在于,指定目录的方式不同,chdir()是以路径的方式进行指定,而fchdir()则是通过文件描述符,文件描述符可调用open()打开相应的目录时获得。
测试
示例代码 5.8.6 chdir函数使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main(void)
{
char buf[100];
char*ptr;
int ret;
/* 获取更改前的工作目录 */
memset(buf,0x0,sizeof(buf));
ptr = getcwd(buf,sizeof(buf));
if(NULL== ptr){
perror("getcwd error");
exit(-1);
}
printf("Before the change: %s\n", buf);
/* 更改进程的当前工作目录 */
ret = chdir("./new_dir");
if(-1== ret){
perror("chdir error");
exit(-1);
}
/* 获取更改后的工作目录 */
memset(buf,0x0,sizeof(buf));
ptr = getcwd(buf,sizeof(buf));
if(NULL== ptr){
perror("getcwd error");
exit(-1);
}
printf("After the change: %s\n", buf);
exit(0);
}
上述程序会在更改工作目录之前获取当前工作目录、并将其打印出来,之后调用chdir函数将进程的工作目录更改为当前目录下的new_dir目录,更改成功之后再将进程的当前工作目录获取并打印出来,接下来编译测试:
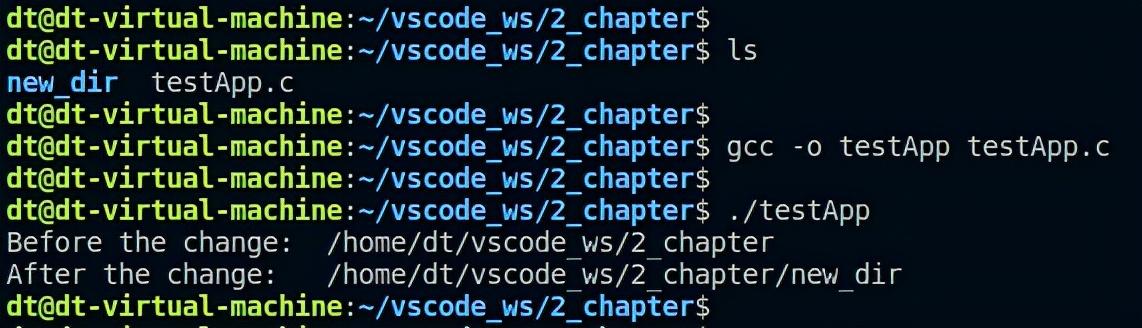
图 5.8.6 编译运行
删除文件
前面给大家介绍了如何删除一个目录,使用rmdir()函数即可,显然该函数并不能删除一个普通文件,那如何删除一个普通文件呢?方法就是通过系统调用unlink()或使用C库函数remove()。
使用unlink函数删除文件
unlink()用于删除一个文件(不包括目录),函数原型如下所示:
#include <unistd.h>
int unlink(const char *pathname);
使用该函数需要包含头文件<unistd.h>。
函数参数和返回值含义如下:
pathname:需要删除的文件路径,可使用相对路径、也可使用绝对路径,如果pathname参数指定的文件不存在,则调用unlink()失败。
返回值:成功返回0;失败将返回-1,并设置errno。
前面给大家介绍link函数,用于创建一个硬链接文件,创建硬链接时,inode节点上的链接数就会增加;unlink()的作用与link()相反,unlink()系统调用用于移除/删除一个硬链接(从其父级目录下删除该目录条目)。
所以unlink()系统调用实质上是移除pathname参数指定的文件路径对应的目录项(从其父级目录中移除该目录项),并将文件的inode链接计数将1,如果该文件还有其它硬链接,则任可通过其它链接访问该文件的数据;只有当链接计数变为0时,该文件的内容才可被删除。另一个条件也会阻止删除文件的内容---只要有进程打开了该文件,其内容也不能被删除。关闭一个文件时,内核会检查打开该文件的进程个数,如果这个计数达到0,内核再去检查其链接计数,如果链接计数也是0,那么就删除该文件对应的内容(也就是文件对应的inode以及数据块被回收,如果一个文件存在多个硬链接,删除其中任何一个硬链接,其inode和数据块并没有被回收,还可通过其它硬链接访问文件的数据)。
unlink()系统调用并不会对软链接进行解引用操作,若pathname指定的文件为软链接文件,则删除软链接文件本身,而非软链接所指定的文件。
测试
示例代码 5.9.1 unlink函数使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
int ret;
ret = unlink("./test_file");
if(-1== ret){
perror("unlink error");
exit(-1);
}
exit(0);
}
上述代码调用unlink()删除当前目录下的test_file文件,编译测试:
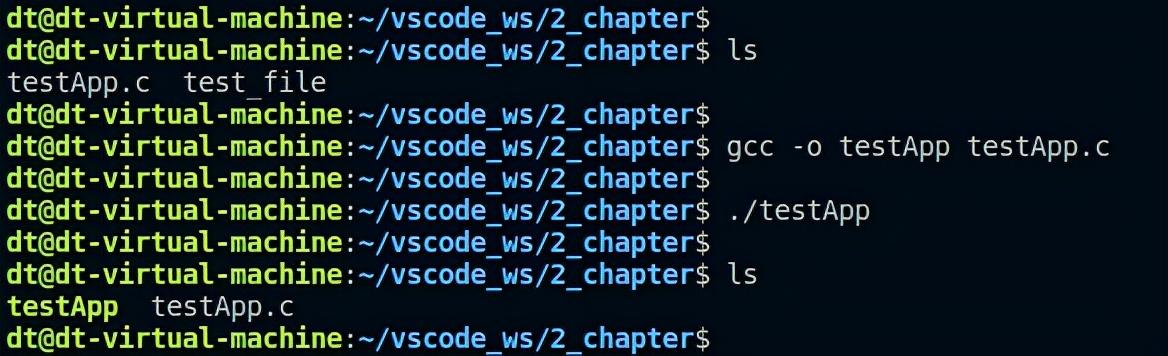
图 5.9.1 unlink删除文件
使用remove函数删除文件
remove()是一个C库函数,用于移除一个文件或空目录,其函数原型如下所示:
#include <stdio.h>
int remove(const char *pathname);
使用该函数需要包含C库函数头文件<stdio.h>。
函数参数和返回值含义如下:
pathname:需要删除的文件或目录路径,可以是相对路径、也可是决定路径。
返回值:成功返回0;失败将返回-1,并设置errno。
pathname参数指定的是一个非目录文件,那么remove()去调用unlink(),如果pathname参数指定的是一个目录,那么remove()去调用rmdir()。
与unlink()、rmdir()一样,remove()不对软链接进行解引用操作,若pathname参数指定的是一个软链接文件,则remove()会删除链接文件本身、而非所指向的文件。
测试
示例代码 5.9.2 remove函数使用示例
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int ret;
ret = remove("./test_file");
if(-1== ret){
perror("remove error");
exit(-1);
}
exit(0);
}
文件重命名
本小节给大家介绍rename()系统调用,借助于rename()既可以对文件进行重命名,又可以将文件移至同一文件系统中的另一个目录下,其函数原型如下所示:
#include <stdio.h>
int rename(const char *oldpath, const char *newpath);
使用该函数需要包含头文件<stdio.h>。
函数参数和返回值含义如下:
oldpath:原文件路径。
newpath:新文件路径。
返回值:成功返回0;失败将返回-1,并设置errno。
调用rename()会将现有的一个路径名oldpath重命名为newpath参数所指定的路径名。rename()调用仅操作目录条目,而不移动文件数据(不改变文件inode编号、不移动文件数据块中存储的内容),重命名既不影响指向该文件的其它硬链接,也不影响已经打开该文件的进程(譬如,在重命名之前该文件已被其它进程打开了,而且还未被关闭)。
根据oldpath、newpath的不同,有以下不同的情况需要进行说明:
若newpath参数指定的文件或目录已经存在,则将其覆盖;若newpath和oldpath指向同一个文件,则不发生变化(且调用成功)。rename()系统调用对其两个参数中的软链接均不进行解引用。如果oldpath是一个软链接,那么将重命名该软链接;如果newpath是一个软链接,则会将其移除、被覆盖。如果oldpath指代文件,而非目录,那么就不能将newpath指定为一个目录的路径名。要想重命名一个文件到某一个目录下,newpath必须包含新的文件名。如果oldpath指代为一个目录,在这种情况下,newpath要么不存在,要么必须指定为一个空目录。oldpath和newpath所指代的文件必须位于同一文件系统。由前面的介绍,可以得出此结论!不能对.(当前目录)和..(上一级目录)进行重命名。
测试
示例代码 5.10.1 rename函数使用示例
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int ret;
ret = rename("./test_file","./new_file");
if(-1== ret){
perror("rename error");
exit(-1);
}
exit(0);
}
将当前目录下的test_file文件重命名为new_file,接下来编译测试:
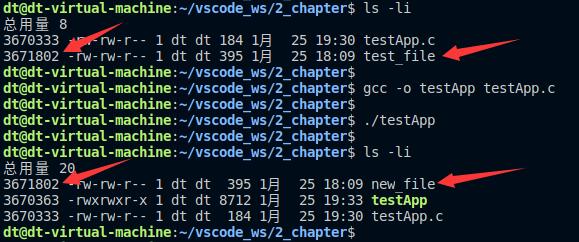
图 5.10.1 rename重命名
从图中可以知道,使用rename进行文件重命名之后,其inode号并未改变。
总结
本章所介绍的内容比较多,主要是围绕文件属性以及目录展开的一系列相关话题,本章开头先给大家介绍Linux系统下的7种文件类型,包括普通文件、目录、设备文件(字符设备文件、块设备文件)、符号链接文件(软链接文件)、管道文件以及套接字文件。
接着围绕stat系统调用,详细给大家介绍了struct stat结构体中的每一个成员,这使得我们对Linux下文件的各个属性都有所了解。接着分别给大家详细介绍了文件属主、文件访问权限、文件时间戳、软链接与硬链接以及目录等相关内容,让大家知道在应用编程中如何去修改文件的这些属性以及它们所需要满足的条件。
至此,本章内容到这里就结束了,相信大家已经学习到了不少知识内容,大家加油! |